Strings
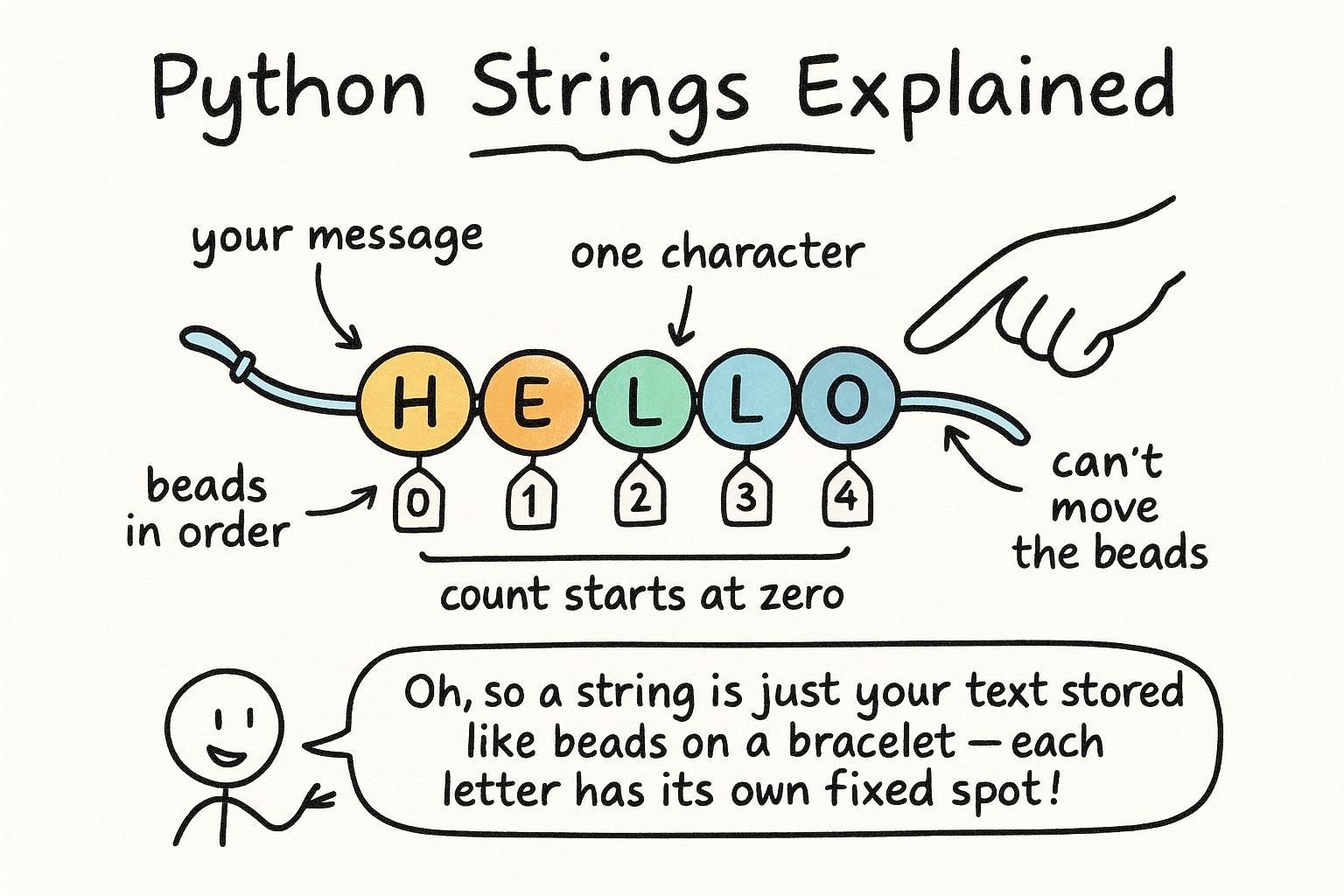
Text shows up in almost every program you write. Names, messages, scores, labels. In Python, any piece of text is called a string: any value you wrap in quote marks. Single or double, both work the same way.
greeting = "Hello, world"
username = 'alice'The only time the choice of quotes matters is when your text contains quote marks. Use the opposite style so you don't have to escape them:
note = "It's a great day" # apostrophe inside, use double quotes
message = 'She said "hello"' # double quotes inside, use single quotes
escaped = "She said \"hello\"" # or escape with a backslashImmutability
Strings are immutable: once you create one, you cannot change it. Think of a string as permanently fixed the moment it is made. Any operation that looks like it is modifying a string is actually producing a brand new one. The original stays exactly as it was.
name = "alice"
name = name.upper() # "ALICE" is a new string; "alice" is unchangedThe direct consequence: you cannot change a character at a specific position. Python will raise an error if you try.
name = "alice"
name[0] = "A" # TypeError: 'str' object does not support item assignmentTo get a modified string, build a new one using slicing or a method. Both are covered below.

name[0] = "A" doesn't work, it raises a TypeError. Indexing and slicing
Every character in a string has a numbered position, starting at zero. You can read individual characters by putting that position number in square brackets. Negative numbers count backward from the end.
word = "Python"
# 012345
print(word[0]) # "P"
print(word[2]) # "t"
print(word[5]) # "n"
print(word[-1]) # "n" (last character)
print(word[-2]) # "o" (second to last)-1 is always the last character, -2 the second to last, and so on. They are useful when you want the end of a string without knowing its exact length.
Slicing extracts a chunk. [start:stop] includes start and excludes stop:
word = "Python"
print(word[0:2]) # "Py" (positions 0 and 1)
print(word[2:]) # "thon" (position 2 to end)
print(word[:3]) # "Pyt" (start to position 2)
print(word[:]) # "Python" (a copy of the whole string)
print(word[::2]) # "Pto" (every second character)
print(word[::-1]) # "nohtyP" (reversed)Three patterns to reach for most: word[:n] for the first n characters, word[n:] for everything from position n onward, word[-n:] for the last n characters. word[::-1] reverses a string. It looks odd the first time, but it is idiomatic Python and you will see it often.
word[0] is the first character and word[-1] is the last. A slice grabs a range: word[start:stop] keeps start and stops right before stop. word[::-1] reverses the string, which looks strange the first time and then you use it forever. Essential string methods
Strings come with a set of built-in methods: operations you call directly on any string value. You write the string (or the variable holding it), then a dot, then the method name. Each method returns a new string. The original is never changed.
Case
text = "Hello, World"
text.lower() # "hello, world"
text.upper() # "HELLO, WORLD"
text.title() # "Hello, World" (each word capitalised)
text.capitalize() # "Hello, world" (first word only)lower() and upper() are the two you will use most. lower() is particularly useful when comparing text: "Alice" and "alice" become the same thing once you call .lower() on both sides.
Whitespace
text = " hello "
text.strip() # "hello" (both sides)
text.lstrip() # "hello " (left only)
text.rstrip() # " hello" (right only)strip() removes spaces from both ends of a string. You will use it almost any time you handle user input or text from a file, because stray spaces cause silent failures: "alice" != "alice ".
Finding
text = "Hello, world"
text.find("world") # 7
text.find("Python") # -1 (not found)
text.count("l") # 3
text.startswith("Hello") # True
text.endswith("world") # Truefind() returns the position where a piece of text starts inside your string. If it is not there, it returns -1. Use startswith() and endswith() when you only care whether the string begins or ends with something specific.
Replacing
text = "Hello, world"
text.replace("world", "Python") # "Hello, Python"
text.replace("l", "L") # "HeLLo, worLd" (all occurrences)
text.replace("l", "L", 1) # "HeLlo, world" (first only)replace() swaps every occurrence of one piece of text for another and gives you back a new string. The original is not changed. Pass a third argument if you only want to replace the first occurrence.
Splitting and joining
split() cuts a string into pieces at a separator and returns them as a list. You tell it what to cut on:
csv_row = "Alice,28,London"
parts = csv_row.split(",") # ["Alice", "28", "London"]
" hello world ".split() # ["hello", "world"]split() returns a list, an ordered sequence of values. They get their own Lists chapter; for now treat them as the sequence of parts split() produces and join() consumes.
join() does the reverse: it combines a list of strings into one. The string before .join() is placed between each item:
words = ["Hello", "world"]
" ".join(words) # "Hello world"
", ".join(words) # "Hello, world"
"".join(words) # "Helloworld"The pattern to remember: separator.join(list_of_strings). The separator goes on the left, the list on the right. " ".join(words) puts a space between each word. "".join(words) glues them with nothing between.
.lower() and .upper() for case, .strip() to trim stray spaces, .find() to locate text (it returns -1 when it's not there), .replace() to swap text, and .split() with sep.join() to take a string apart and put it back together. f-strings
f-strings embed values directly inside text. Put f before the opening quote, then wrap any variable or expression in curly braces. Python fills it in when the code runs. You can also add a colon after the value to control how it is displayed.
name = "Alice"
score = 94.5
print(f"Hello, {name}!") # "Hello, Alice!"
print(f"Score: {score:.1f}%") # "Score: 94.5%"
print(f"2 + 2 = {2 + 2}") # "2 + 2 = 4"
print(f"Name: {name.upper()}") # "Name: ALICE"The format spec after : controls how the value is displayed:
| Spec | Meaning | Example |
|---|---|---|
.2f | 2 decimal places | f"{3.14159:.2f}" → "3.14" |
.0% | percentage, no decimals | f"{0.94:.0%}" → "94%" |
, | thousands separator | f"{1000000:,}" → "1,000,000" |
>10 | right-align in 10 chars | f"{'hi':>10}" → " hi" |
You will use .2f most: any time you display a decimal and want a tidy number rather than a long run of digits. Everything else in the table is there when you need it. You can put any variable, arithmetic, or method call inside the {}.
f before the opening quote, then wrap any variable, sum, or method call in {} and Python drops the result in when the line runs. A colon inside the braces controls the look: :.2f for two decimal places is the one you'll lean on. So much tidier than gluing text together with +. Multiline strings
To write a string that spans more than one line, use triple quote marks: three " at the start and three at the end. Python preserves all the line breaks and spacing exactly as you wrote them.
message = """
Dear Alice,
Thank you for your order.
Best regards,
The Team
"""Escape sequences
Some characters are hard to type directly inside a string. Python uses escape sequences: a backslash followed by a letter that stands for something. The two you will use constantly are \n for a new line and \t for a tab.
| Sequence | Character |
|---|---|
\n | Newline |
\t | Tab |
\\ | Literal backslash |
\" | Double quote |
\' | Single quote |
print("Line one\nLine two") # two lines of output
print("Name:\tAlice") # Name: Alice
path = r"C:\Users\Alice\Documents" # raw string, no escape processing\n starts a new line, \t inserts a tab, \\ is one real backslash. Those two, \n and \t, are the ones you'll actually type. Pop an r before the quote and backslashes go back to being plain, handy for Windows paths. Checking string contents
Python has methods that answer yes/no questions about what a string contains. They return True or False. The most useful early on: isdigit() lets you check whether a string is all numbers before converting it, so you can avoid a crash on unexpected input.
"42".isdigit() # True
"hello".isalpha() # True
"hello42".isalnum() # True
" ".isspace() # True
"Hello".islower() # False
"HELLO".isupper() # Trueis* methods answer yes-or-no questions and return True only when every character fits. The one you'll use first: call isdigit() before int() to make sure the text really is a number, so odd input doesn't crash you. In practice
Strip whitespace, normalise case, then pull out what you need. This sequence handles almost any user-provided text:
raw_input = " [email protected] "
email = raw_input.strip().lower() # "[email protected]"
at_pos = email.find("@")
username = email[:at_pos]
domain = email[at_pos + 1:]
print(f"User: {username}") # "alice"
print(f"Domain: {domain}") # "example.com"Method reference
| Method | What it does |
|---|---|
.lower() / .upper() | Convert to all lowercase / all uppercase |
.title() / .capitalize() | Capitalise each word / only the first |
.strip() / .lstrip() / .rstrip() | Remove surrounding whitespace |
.find(sub) | Index of first match, or -1 |
.count(sub) | How many times sub appears |
.startswith(s) / .endswith(s) | Prefix / suffix check |
.replace(old, new) | Replace occurrences |
.split(sep) | Split into a list |
sep.join(iterable) | Join items into a string |
.isdigit() / .isalpha() / .isalnum() | Character type checks |