文字列
テキストはほぼすべてのプログラムに登場します。名前、メッセージ、スコア、ラベル。Pythonでは、テキストの一部を文字列と呼びます。引用符で囲んだすべての値です。シングルでもダブルでも、どちらでも同じように機能します。
greeting = "Hello, world"
username = 'tanaka'引用符の選択が重要になるのは、テキストに引用符が含まれている場合のみです。エスケープを避けるために反対のスタイルを使用してください。
note = "It's a great day" # アポストロフィの内側、ダブルクォートを使用
message = 'She said "hello"' # ダブルクォートの内側、シングルクォートを使用
escaped = "She said \"hello\"" # またはバックスラッシュでエスケープ不変性
文字列は不変です。一度作成したら、それを変更することはできません。文字列を作成した瞬間に永久に固定されたものと考えてください。文字列を変更しているように見えるすべての操作は、実は新しい文字列を生成しているだけです。元の文字列は正確に保たれます。
name = "tanaka"
name = name.upper() # "TANAKA"は新しい文字列、"tanaka"は変わらない直接的な結果:特定の位置の文字を変更することはできません。Pythonは試行時にエラーを発生させます。
name = "tanaka"
name[0] = "T" # TypeError: 'str' object does not support item assignment変更された文字列を取得するには、スライスまたはメソッドを使用して新しい文字列を構築します。両方とも以下で説明されています。

name[0] = "T"は機能しません。TypeErrorを発生させます。 インデックスとスライス
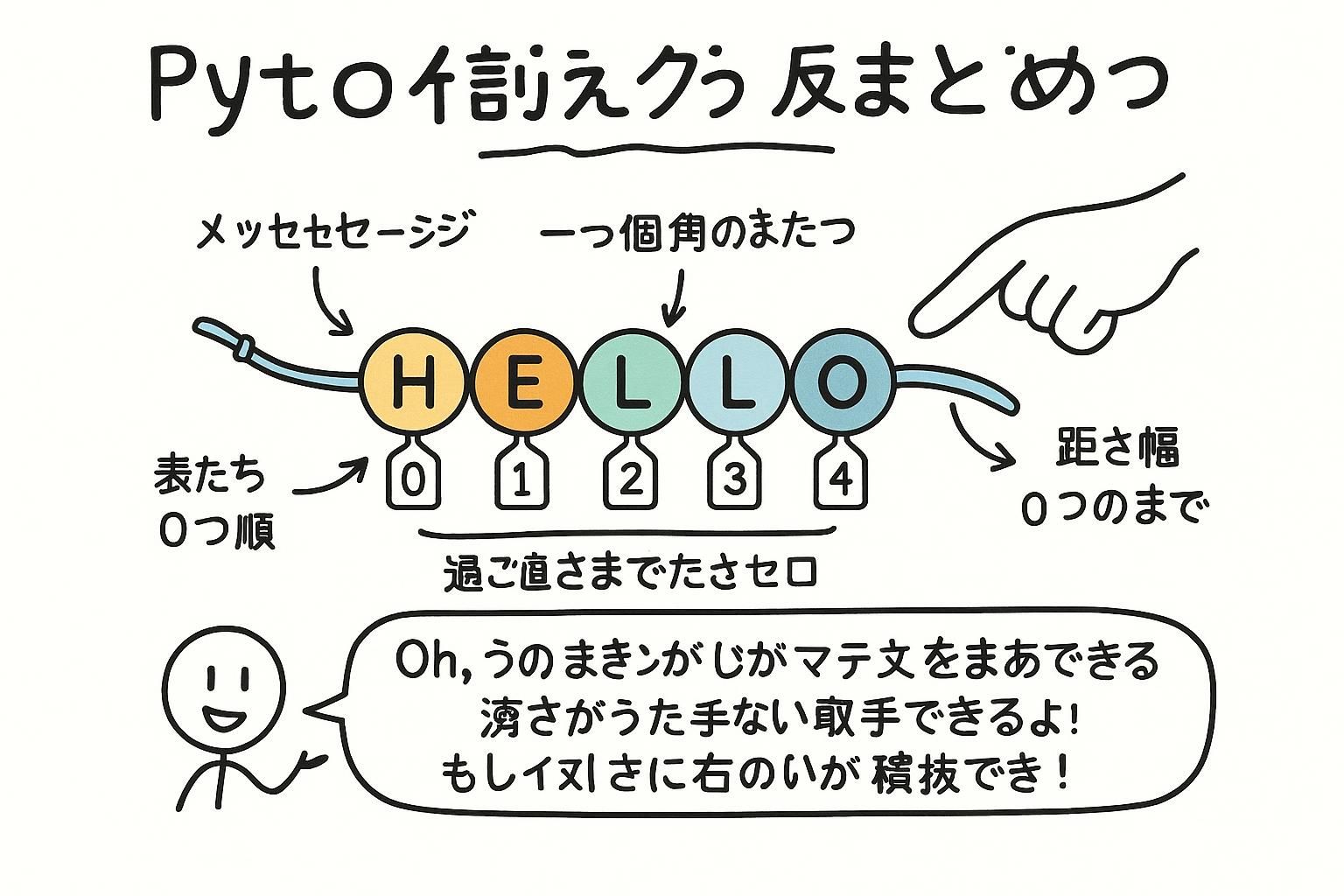
文字列のすべての文字には、ゼロから始まる番号付きの位置があります。その位置番号を角括弧に入れることで、個々の文字を読むことができます。負の数は末尾から逆向きにカウントされます。
word = "Python"
# 012345
print(word[0]) # "P"
print(word[2]) # "t"
print(word[5]) # "n"
print(word[-1]) # "n" (最後の文字)
print(word[-2]) # "o" (最後から2番目)-1は常に最後の文字、-2は最後から2番目、というように続きます。正確な長さを知らずに文字列の末尾にアクセスしたい場合に便利です。
スライスはチャンクを抽出します。[start:stop]はstartを含み、stopは除外します。
word = "Python"
print(word[0:2]) # "Py" (位置0と1)
print(word[2:]) # "thon" (位置2から末尾まで)
print(word[:3]) # "Pyt" (開始から位置2まで)
print(word[:]) # "Python" (文字列全体のコピー)
print(word[::2]) # "Pto" (毎秒番目の文字)
print(word[::-1]) # "nohtyP" (反転)最も使用する3つのパターン:最初のn文字にはword[:n]、位置nからそれ以降のすべてにはword[n:]、最後のn文字にはword[-n:]。word[::-1]は文字列を反転させます。最初は奇妙に見えますが、それはイディオマティックなPythonで、頻繁に見かけます。
word[0]は最初の文字で、word[-1]は最後です。スライスは範囲をグラブします。word[start:stop]はstartを保ち、stopの直前で停止します。word[::-1]は文字列を反転させ、最初は奇妙に見えて、その後ずっと使用します。 基本的な文字列メソッド
文字列には、組み込みメソッドのセットが付属しています。任意の文字列値で直接呼び出す操作です。文字列(またはそれを保持する変数)、ドット、メソッド名を書きます。各メソッドは新しい文字列を返します。元の文字列は決して変わりません。
ケース
text = "Hello, World"
text.lower() # "hello, world"
text.upper() # "HELLO, WORLD"
text.title() # "Hello, World" (各単語を大文字化)
text.capitalize() # "Hello, world" (最初の単語のみ)lower()とupper()はあなたが最も使うであろう2つです。lower()は特に、テキストを比較する場合に便利です。"Tanaka"と"tanaka"は両側で.lower()を呼び出すと同じになります。
空白
text = " hello "
text.strip() # "hello" (両側)
text.lstrip() # "hello " (左のみ)
text.rstrip() # " hello" (右のみ)strip()は文字列の両側からスペースを削除します。ユーザー入力またはファイルからテキストを処理するとき、ほぼ毎回それを使用します。余分なスペースはサイレント失敗を引き起こすため。"tanaka" != "tanaka "です。
検索
text = "Hello, world"
text.find("world") # 7
text.find("Python") # -1 (見つかりません)
text.count("l") # 3
text.startswith("Hello") # True
text.endswith("world") # Truefind()は、テキストの片が文字列内で開始される位置を返します。そこにない場合は、-1を返します。startswith()とendswith()は、文字列が何か特定で始まるか終わるかだけを気にする場合に使用してください。
置換
text = "Hello, world"
text.replace("world", "Python") # "Hello, Python"
text.replace("l", "L") # "HeLLo, worLd" (すべての出現)
text.replace("l", "L", 1) # "HeLlo, world" (最初のみ)replace()はテキストの1つの部分を別のもので交換し、新しい文字列を返します。元は変わりません。最初の出現のみを置換したい場合は、3番目の引数を渡してください。
分割と結合
split()は文字列をセパレータで部分に切って、リストとして返します。切断するものを指定します。
csv_row = "Tanaka,28,Tokyo"
parts = csv_row.split(",") # ["Tanaka", "28", "Tokyo"]
" hello world ".split() # ["hello", "world"]split()はリストを返します。値の順序付きシーケンスです。彼らは自分たちのリスト章を取得します。今のところsplit()が生成する部分のシーケンスとして扱い、join()が消費します。
join()は逆を行います。文字列のリストを1つに組み合わせます。.join()の前の文字列は各アイテムの間に配置されます。
words = ["Hello", "world"]
" ".join(words) # "Hello world"
", ".join(words) # "Hello, world"
"".join(words) # "Helloworld"覚えておくパターン:separator.join(list_of_strings)。セパレータは左側に、リストは右側にあります。" ".join(words)は各単語の間にスペースを配置します。"".join(words)はそれらをつなぎます。
.lower()と.upper()のケース、スペースをトリムするための.strip()、テキストを位置する.find()(そこにない場合は-1を返す)、テキストをスワップするための.replace()、および文字列を分割してsep.join()で一緒に戻すための.split()。 f文字列
f文字列はテキスト内に値を直接埋め込みます。開く引用符の前にfを置き、任意の変数または式を中括弧で囲みます。コードが実行されるとき、Pythonはそれを埋めます。また、値の後にコロンを追加して、表示方法を制御できます。
name = "Tanaka"
score = 94.5
print(f"Hello, {name}!") # "Hello, Tanaka!"
print(f"Score: {score:.1f}%") # "Score: 94.5%"
print(f"2 + 2 = {2 + 2}") # "2 + 2 = 4"
print(f"Name: {name.upper()}") # "Name: TANAKA":の後のフォーマット仕様は値の表示方法を制御します。
| 仕様 | 意味 | 例 |
|---|---|---|
.2f | 小数点以下2桁 | f"{3.14159:.2f}" → "3.14" |
.0% | パーセンテージ、小数点なし | f"{0.94:.0%}" → "94%" |
, | 千の位の区切り | f"{1000000:,}" → "1,000,000" |
>10 | 10文字で右配置 | f"{'hi':>10}" → " hi" |
最も使用するのは.2fです。小数を表示してきちんとした数字を望む場合は常に、長い実行数字ではなく。テーブルの他のすべては、それが必要な場合がそこにあります。{}の内側に任意の変数、算術、またはメソッド呼び出しを入れることができます。
fを置き、任意の変数、合計、またはメソッド呼び出しを{}で囲み、行が実行されるとPythonは結果をドロップします。中括弧内のコロンは、外観を制御します。:.2fは2つの小数点は、あなたが身を寄せるだろうと思います。`+`でテキストを一緒に接着するよりもはるかにきちんとしています。 複数行文字列
複数行にわたる文字列を書くには、トリプルクォートマークを使用します。開始時に3つの"と終了時に3つです。Pythonは、記入したとおりに正確にすべての改行とスペースを保持します。
message = """
Dear Tanaka,
Thank you for your order.
Best regards,
The Team
"""エスケープシーケンス
いくつかの文字は文字列内で直接入力するのが難しいです。Pythonはエスケープシーケンスを使用します。何かを表すバックスラッシュに続く文字です。あなたが常に使う2つは、新しい行に\n、タブに\tです。
| シーケンス | 文字 |
|---|---|
\n | 改行 |
\t | タブ |
\\ | リテラルバックスラッシュ |
\" | ダブルクォート |
\' | シングルクォート |
print("Line one\nLine two") # 2行の出力
print("Name:\tTanaka") # Name: Tanaka
path = r"C:\Users\Tanaka\Documents" # 生文字列、エスケープ処理なし文字列内容を確認
Pythonには、文字列に含まれているものについてのはい/いいえの質問に答えるメソッドがあります。彼らはTrueまたはFalseを返します。最初は有用です。isdigit()を使用すると、変換前に文字列がすべて数字であるかを確認できるため、予期しない入力でクラッシュを避けることができます。
"42".isdigit() # True
"hello".isalpha() # True
"hello42".isalnum() # True
" ".isspace() # True
"Hello".islower() # False
"HELLO".isupper() # True実践
空白をストリップし、ケースを正規化し、その後、必要なものを引き出します。このシーケンスはほぼすべてのユーザー提供テキストを処理します。
raw_input = " [email protected] "
email = raw_input.strip().lower() # "[email protected]"
at_pos = email.find("@")
username = email[:at_pos]
domain = email[at_pos + 1:]
print(f"User: {username}") # "tanaka"
print(f"Domain: {domain}") # "example.com"メソッドリファレンス
| メソッド | 何をするか |
|---|---|
.lower() / .upper() | すべて小文字/大文字に変換 |
.title() / .capitalize() | 各単語を大文字化/最初のみ |
.strip() / .lstrip() / .rstrip() | 周辺の空白を削除 |
.find(sub) | 最初の一致のインデックス、または-1 |
.count(sub) | subが表示される回数 |
.startswith(s) / .endswith(s) | プレフィックス/サフィックスチェック |
.replace(old, new) | 出現を置換 |
.split(sep) | リストに分割 |
sep.join(iterable) | アイテムを文字列に結合 |
.isdigit() / .isalpha() / .isalnum() | 文字型チェック |