문자열
작성하는 거의 모든 프로그램에 텍스트가 나타납니다. 이름, 메시지, 점수, 레이블. Python에서 모든 텍스트는 문자열이라고 불립니다: 따옴표로 감싼 모든 값. 홑따옴표든 쌍따옴표든 둘 다 같은 방식으로 작동합니다.
greeting = "Hello, world"
username = 'alice'따옴표 선택이 중요한 유일한 경우는 텍스트에 따옴표가 포함될 때입니다. 반대 스타일을 사용하면 이스케이프할 필요가 없습니다:
note = "It's a great day" # 아포스트로피 내부, 쌍따옴표 사용
message = 'She said "hello"' # 쌍따옴표 내부, 홑따옴표 사용
escaped = "She said \"hello\"" # 또는 백슬래시로 이스케이프불변성
문자열은 불변입니다: 한 번 생성하면 변경할 수 없습니다. 문자열을 생성되는 순간 영구적으로 고정된 것으로 생각하세요. 문자열을 수정하는 것처럼 보이는 모든 작업은 실제로 새로운 것을 생성합니다. 원본은 정확히 그대로 유지됩니다.
name = "alice"
name = name.upper() # "ALICE"는 새로운 문자열입니다; "alice"는 변경되지 않음직접적인 결과: 특정 위치의 문자를 변경할 수 없습니다. 시도하면 Python이 오류를 발생시킵니다.
name = "alice"
name[0] = "A" # TypeError: 'str' object does not support item assignment수정된 문자열을 얻으려면 슬라이싱이나 메서드를 사용하여 새로운 문자열을 만드세요. 둘 다 아래에서 다룹니다.

name[0] = "A"는 작동하지 않습니다. TypeError를 발생시킵니다. 인덱싱과 슬라이싱
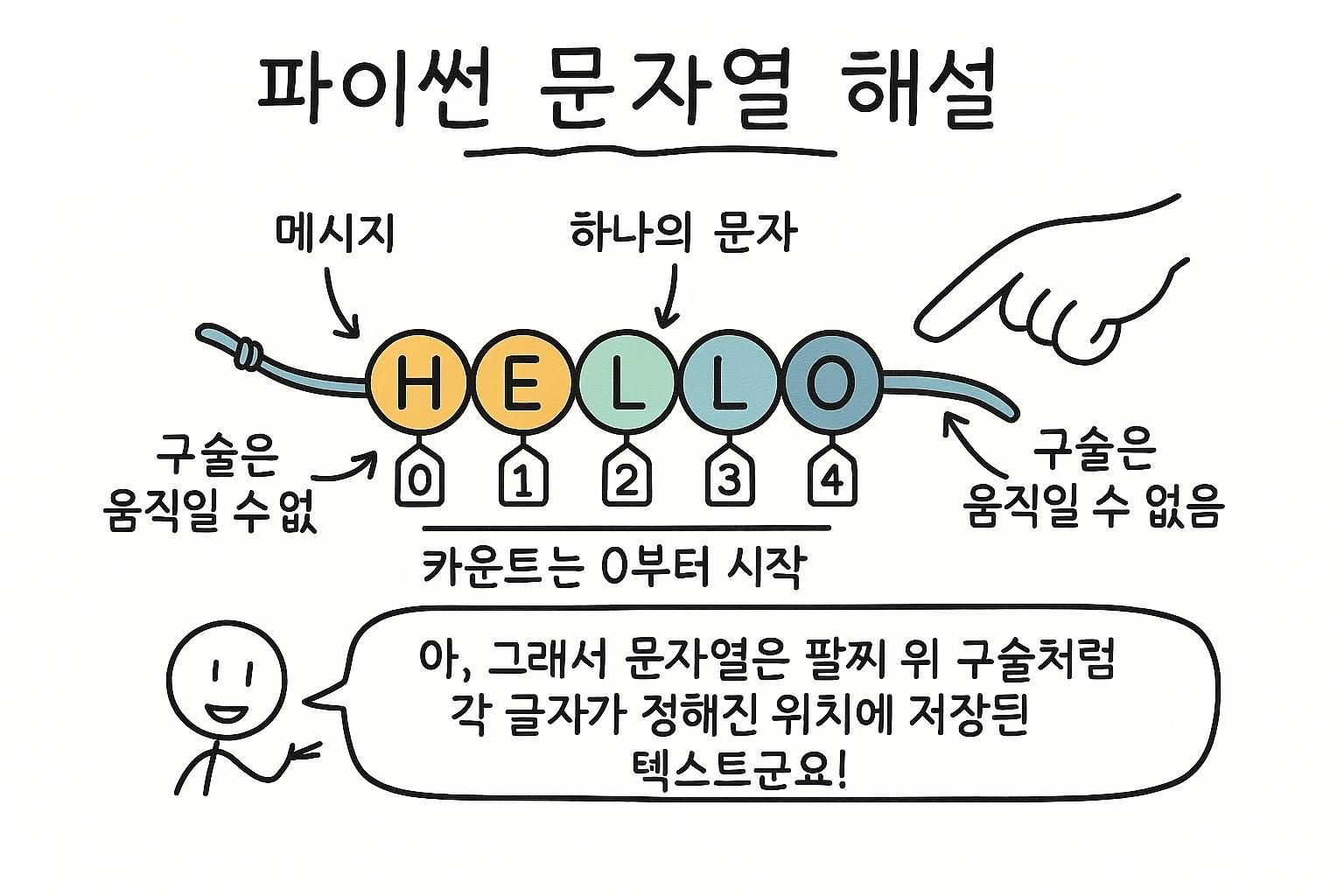
문자열의 모든 문자는 0부터 시작하는 번호가 매겨진 위치를 가집니다. 그 위치 번호를 대괄호에 넣어 개별 문자를 읽을 수 있습니다. 음수는 끝에서 역순으로 계산합니다.
word = "Python"
# 012345
print(word[0]) # "P"
print(word[2]) # "t"
print(word[5]) # "n"
print(word[-1]) # "n" (마지막 문자)
print(word[-2]) # "o" (끝에서 두 번째)-1은 항상 마지막 문자, -2는 끝에서 두 번째이고, 등등입니다. 정확한 길이를 모르면서 문자열의 끝을 원할 때 유용합니다.
슬라이싱은 청크를 추출합니다. [start:stop]은 start를 포함하고 stop을 제외합니다:
word = "Python"
print(word[0:2]) # "Py" (위치 0과 1)
print(word[2:]) # "thon" (위치 2부터 끝)
print(word[:3]) # "Pyt" (시작부터 위치 2)
print(word[:]) # "Python" (전체 문자열 복사)
print(word[::2]) # "Pto" (모든 두 번째 문자)
print(word[::-1]) # "nohtyP" (역순)대부분 사용할 세 가지 패턴: word[:n]은 처음 n개 문자, word[n:]은 위치 n부터 모든 것, word[-n:]은 마지막 n개 문자. word[::-1]은 문자열을 역순으로 만듭니다. 처음에는 이상해 보이지만 관례적인 Python이고 자주 보게 됩니다.
word[0]은 첫 번째 문자이고 word[-1]은 마지막입니다. 슬라이스는 범위를 잡습니다: word[start:stop]은 start를 유지하고 stop 직전에 멈춥니다. word[::-1]은 문자열을 역순으로 만듭니다. 처음에는 이상하게 보이다가 영원히 사용합니다. 필수 문자열 메서드
문자열은 기본 제공 메서드 세트와 함께 제공됩니다: 모든 문자열 값에서 직접 호출하는 작업. 문자열(또는 그것을 보유한 변수)을 쓴 다음 점을 쓴 다음 메서드 이름을 씁니다. 각 메서드는 새 문자열을 반환합니다. 원본은 절대 변경되지 않습니다.
경우
text = "Hello, World"
text.lower() # "hello, world"
text.upper() # "HELLO, WORLD"
text.title() # "Hello, World" (각 단어 대문자)
text.capitalize() # "Hello, world" (첫 단어만)lower()와 upper()는 가장 많이 사용할 두 가지입니다. lower()는 텍스트 비교에 특히 유용합니다: "Alice"와 "alice"는 양쪽에서 .lower()를 호출하면 같은 것이 됩니다.
공백
text = " hello "
text.strip() # "hello" (양쪽)
text.lstrip() # "hello " (왼쪽만)
text.rstrip() # " hello" (오른쪽만)strip()은 문자열의 양쪽 끝에서 공백을 제거합니다. 사용자 입력이나 파일의 텍스트를 처리할 거의 모든 경우에 사용할 것입니다. 왜냐하면 여분의 공백은 조용한 실패를 유발하기 때문입니다: "alice" != "alice ".
찾기
text = "Hello, world"
text.find("world") # 7
text.find("Python") # -1 (찾을 수 없음)
text.count("l") # 3
text.startswith("Hello") # True
text.endswith("world") # Truefind()는 텍스트가 문자열 내에서 시작하는 위치를 반환합니다. 그곳에 없으면 -1을 반환합니다. 문자열이 특정 문자로 시작하거나 끝나는지만 신경 쓸 때 startswith()와 endswith()를 사용하세요.
바꾸기
text = "Hello, world"
text.replace("world", "Python") # "Hello, Python"
text.replace("l", "L") # "HeLLo, worLd" (모든 항목)
text.replace("l", "L", 1) # "HeLlo, world" (첫 번째만)replace()는 한 텍스트 조각을 다른 텍스트로 교환하고 새 문자열을 반환합니다. 원본은 변경되지 않습니다. 첫 번째 항목만 바꾸려면 세 번째 인수를 전달하세요.
분할 및 결합
split()은 구분 기호에서 문자열을 조각으로 자르고 리스트로 반환합니다. 무엇을 자를지 알려주세요:
csv_row = "Alice,28,Seoul"
parts = csv_row.split(",") # ["Alice", "28", "Seoul"]
" hello world ".split() # ["hello", "world"]split()은 리스트를 반환합니다. 값의 정렬된 시퀀스. 그들은 그들 자신의 Lists 장을 가집니다. 지금은 split()이 생성하는 부분 시퀀스와 join()이 사용하는 것으로 취급하세요.
join()은 반대를 합니다: 문자열 리스트를 하나로 결합합니다. 점 앞의 문자열은 각 항목 사이에 배치됩니다:
words = ["Hello", "world"]
" ".join(words) # "Hello world"
", ".join(words) # "Hello, world"
"".join(words) # "Helloworld"기억할 패턴: separator.join(list_of_strings). 구분 기호는 왼쪽에 가고 리스트는 오른쪽에 갑니다. " ".join(words)는 각 단어 사이에 공백을 넣습니다. "".join(words)는 아무것도 사이에 없이 접착합니다.
.lower()와 .upper(), 여분의 공백을 다듬기 위해 .strip(), 텍스트를 찾기 위해 .find()(불완전할 때 -1 반환), 텍스트를 교환하기 위해 .replace(), 문자열을 분해하고 다시 조합하기 위해 .split()과 sep.join(). f-문자열
f-문자열은 값을 텍스트 내부에 직접 포함합니다. 열기 따옴표 앞에 f를 넣은 다음 중괄호에 모든 변수 또는 표현식을 래핑하세요. Python은 코드가 실행될 때 채웁니다. 값 뒤에 콜론을 추가하여 표시 방식을 제어할 수도 있습니다.
name = "Alice"
score = 94.5
print(f"Hello, {name}!") # "Hello, Alice!"
print(f"Score: {score:.1f}%") # "Score: 94.5%"
print(f"2 + 2 = {2 + 2}") # "2 + 2 = 4"
print(f"Name: {name.upper()}") # "Name: ALICE": 뒤의 형식 사양은 값이 표시되는 방식을 제어합니다:
| Spec | 의미 | 예 |
|---|---|---|
.2f | 소수점 2자리 | f"{3.14159:.2f}" → "3.14" |
.0% | 백분율, 소수점 없음 | f"{0.94:.0%}" → "94%" |
, | 천 단위 구분 기호 | f"{1000000:,}" → "1,000,000" |
>10 | 10자 오른쪽 정렬 | f"{'hi':>10}" → " hi" |
대부분 .2f를 사용할 것입니다: 소수를 표시하고 긴 자릿수 실행보다 정돈된 숫자를 원할 때마다. 표의 다른 모든 것은 필요할 때 거기 있습니다. {}에 모든 변수, 산술 또는 메서드 호출을 넣을 수 있습니다.
f를 넣은 다음 {}에 모든 변수, 합계 또는 메서드 호출을 래핑하고 Python은 선이 실행될 때 결과를 떨어뜨립니다. 중괄호 내의 콜론은 모양을 제어합니다: :.2f 2 소수점은 당신이 기울이는 것입니다. +로 텍스트를 접착하는 것보다 훨씬 더 깔끔합니다. 여러 줄 문자열
한 줄 이상에 걸쳐 있는 문자열을 작성하려면 삼중 따옴표를 사용하세요: 시작에 3개의 "와 끝에 3개. Python은 모든 줄 바꿈과 간격을 입력한 정확히 그대로 유지합니다.
message = """
Dear Alice,
Thank you for your order.
Best regards,
The Team
"""이스케이프 시퀀스
일부 문자는 문자열 내에서 직접 입력하기 어렵습니다. Python은 이스케이프 시퀀스를 사용합니다: 뭔가를 나타내는 문자가 뒤따르는 백슬래시. 당신이 지속적으로 사용할 두 가지: 새 줄을 위해 \n, 탭을 위해 \t.
| 시퀀스 | 문자 |
|---|---|
\n | 줄 바꿈 |
\t | 탭 |
\\ | 리터럴 백슬래시 |
\" | 쌍따옴표 |
\' | 홑따옴표 |
print("Line one\nLine two") # 출력 두 줄
print("Name:\tAlice") # Name: Alice
path = r"C:\Users\Alice\Documents" # 원시 문자열, 이스케이프 처리 없음\n은 새 줄을 시작하고, \t는 탭을 삽입하고, \\는 한 개의 진짜 백슬래시입니다. 이 두 가지, \n과 \t는 실제로 입력할 것들입니다. 따옴표 앞에 r을 누르고 백슬래시는 평문으로 돌아갑니다. Windows 경로에 편합니다. 문자열 콘텐츠 확인
Python은 문자열이 포함된 내용에 대해 예/아니오 질문에 답하는 메서드가 있습니다. True 또는 False를 반환합니다. 초기에 가장 유용한 것: isdigit()은 변환하기 전에 문자열이 모두 숫자인지 확인하므로 예상치 못한 입력에 충돌을 피할 수 있습니다.
"42".isdigit() # True
"hello".isalpha() # True
"hello42".isalnum() # True
" ".isspace() # True
"Hello".islower() # False
"HELLO".isupper() # Trueis* 메서드는 예/아니오 질문에 답하고 모든 문자가 맞을 때만 True를 반환합니다. 처음 사용할 것: 텍스트가 정말 숫자인지 확인하기 위해 int() 전에 isdigit()을 호출하세요. 그래서 이상한 입력은 당신을 충돌하지 않습니다. 실제로
공백을 제거하고 경우를 정규화한 다음 필요한 것을 당겨냅니다. 이 시퀀스는 거의 모든 사용자 제공 텍스트를 처리합니다:
raw_input = " [email protected] "
email = raw_input.strip().lower() # "[email protected]"
at_pos = email.find("@")
username = email[:at_pos]
domain = email[at_pos + 1:]
print(f"User: {username}") # "alice"
print(f"Domain: {domain}") # "example.com"메서드 참조
| 메서드 | 하는 일 |
|---|---|
.lower() / .upper() | 모두 소문자 / 모두 대문자로 변환 |
.title() / .capitalize() | 각 단어 / 첫 단어만 대문자 |
.strip() / .lstrip() / .rstrip() | 주변 공백 제거 |
.find(sub) | 첫 일치의 인덱스, 또는 -1 |
.count(sub) | sub이 나타나는 횟수 |
.startswith(s) / .endswith(s) | 접두사 / 접미사 확인 |
.replace(old, new) | 항목 바꾸기 |
.split(sep) | 리스트로 분할 |
sep.join(iterable) | 항목을 문자열로 결합 |
.isdigit() / .isalpha() / .isalnum() | 문자 타입 체크 |