함수
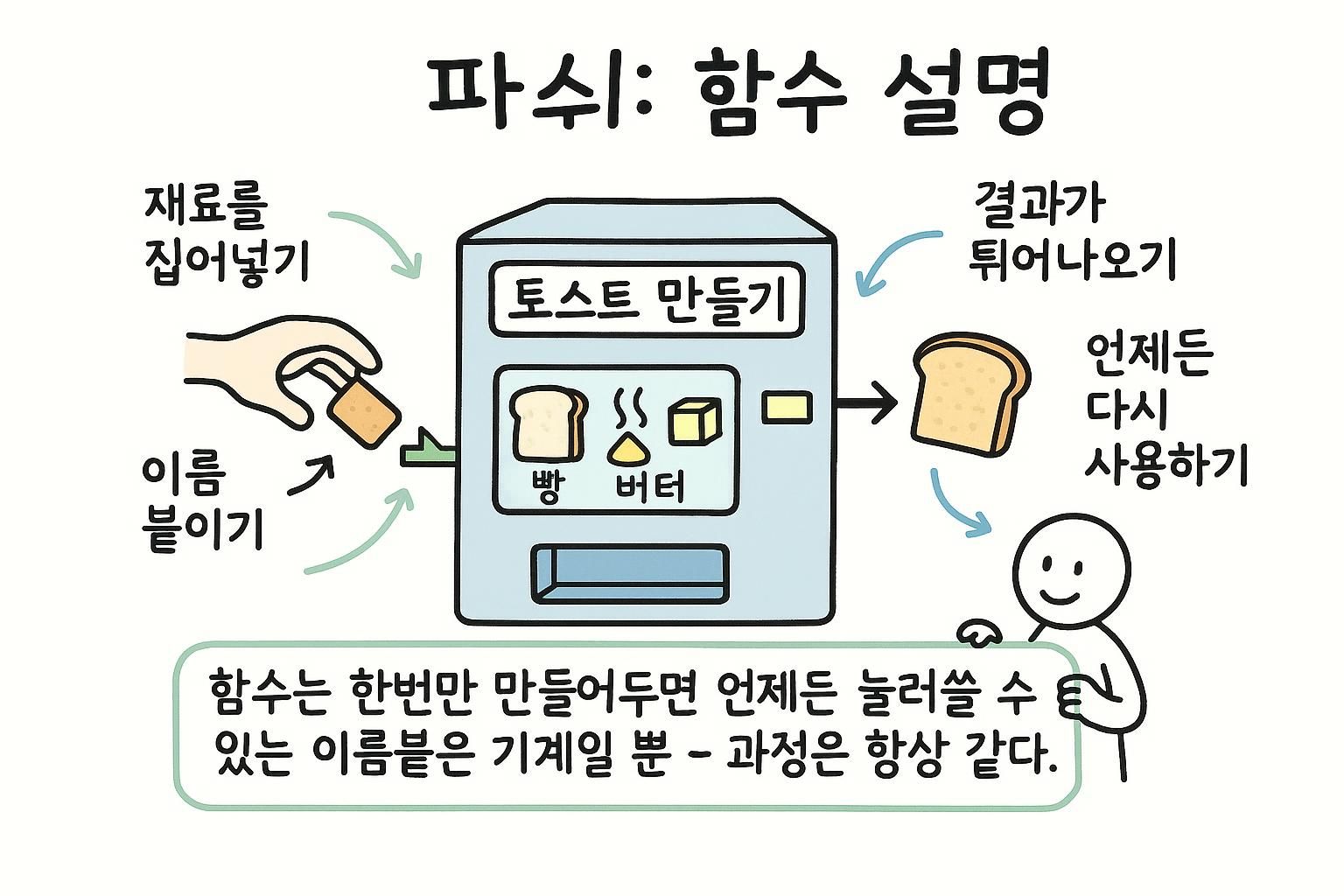
프로그램이 커질수록 여러 곳에서 같은 로직을 작성하게 됩니다. 함수는 로직을 한 번 작성하고, 이름을 붙인 후 어디서든 사용하게 해줍니다. 한 곳에서 수정하면 모든 호출이 자동으로 수정됩니다.
def greet(name):
return f"Hello, {name}!"
print(greet("민지")) # "Hello, 민지!"
print(greet("준호")) # "Hello, 준호!"한 번 작성하고, 어디서든 사용하고, 한 곳에서 수정하세요.
함수 정의하기
def 키워드는 함수 정의를 시작하고, 이름, 괄호, 콜론, 그리고 들여쓰기된 몸체가 따릅니다. 함수는 호출할 때까지 아무것도 하지 않습니다. def로 정의한 후, 이름과 ()로 호출하세요.
def say_hello():
print("Hello!")
say_hello() # 함수 호출
def name():를 작성하고 몸체를 들여쓰세요. name()으로 호출할 때까지 아무것도 일어나지 않으며, def는 그저 설정할 뿐입니다. 그리고 return을 잊으면 함수는 조용히 None을 돌려주는데, 초반에 이게 나를 더 한 번 낚았습니다. 매개변수와 인수
매개변수는 함수가 기대하는 입력값입니다. 괄호 안에 나열하세요. 함수를 호출할 때, 전달하는 값들이 순서대로 매개변수와 일치합니다.
def greet(name, greeting):
print(f"{greeting}, {name}!")
greet("민지", "Hello") # "Hello, 민지!"
greet("준호", "Hi") # "Hi, 준호!"매개변수는 함수 정의의 이름입니다. 인수는 호출할 때 실제로 전달하는 값입니다. 실제로는 사람들이 단어를 바꿔 사용합니다. 구별은 주로 문서를 읽을 때 중요합니다.
기본값
매개변수에 기본값을 줄 수 있습니다. 호출자가 그 인수를 제공하지 않으면 기본값이 사용됩니다. 기본값이 있는 매개변수는 기본값이 없는 매개변수 뒤에 와야 합니다.
def greet(name, greeting="Hello"):
print(f"{greeting}, {name}!")
greet("민지") # "Hello, 민지!"
greet("민지", "Hi") # "Hi, 민지!"기본값이 있는 매개변수는 기본값이 없는 매개변수 뒤에 와야 합니다.
키워드 인수
함수를 호출할 때, 인수를 이름 붙일 수 있습니다. 이렇게 하면 호출이 읽기 쉬워집니다, 특히 많은 매개변수가 있는 함수의 경우, 그리고 어떤 순서로든 전달할 수 있습니다.
def describe_player(name, score, level):
print(f"{name} | Score: {score} | Level: {level}")
describe_player("민지", 87, 5) # 위치
describe_player(name="민지", level=5, score=87) # 키워드, 어떤 순서든
describe_player("민지", level=5, score=87) # 섞기: 위치 먼저score=87), 호출이 자신을 설명하고, 어떤 순서로든 전달할 수 있습니다. 한 가지 규칙: 모든 위치 인수는 이름 붙은 것들 앞에 옵니다. 매개변수가 많은 함수에 좋습니다. 반환값
return은 호출자에게 값을 보냅니다. return이 없으면 함수는 None을 돌려줍니다. return이 실행되면 함수는 즉시 종료됩니다. 그 블록 뒤의 모든 코드는 건너뜁니다.
def add(a, b):
return a + b
result = add(3, 4) # result = 7
print(result)return은 또한 함수를 즉시 종료합니다. 그 블록 뒤의 모든 코드는 실행되지 않습니다.
return은 함수를 호출한 사람에게 값을 돌려주고, 함수는 바로 거기서 멈추며, 그 뒤의 모든 것은 건너뜁니다. return을 빠뜨리면 None을 돌려받습니다. print는 값을 보여주고, return은 그것을 사용하기 위해 돌려줍니다. 그 차이를 느끼는 데 시간이 걸렸습니다. 여러 값 반환하기
Python을 사용하면 쉼표로 구분하여 여러 값을 반환할 수 있습니다. 호출자는 그것들을 튜플로 받고 한 줄에서 별도의 이름으로 언팩할 수 있습니다.
def min_max(numbers):
return min(numbers), max(numbers)
low, high = min_max([3, 7, 1, 9, 4])
print(low, high) # 1 9low, high = ... 신택스는 언팩입니다: Python은 각 반환된 값을 해당하는 이름에 할당합니다.
스코프
함수 내부에 생성된 변수는 그 함수 내부에만 존재합니다. 외부에서 그들을 볼 수 없습니다. 모든 함수 외부에 정의된 변수는 어디서나 보입니다만, 명시적 선언 없이 함수 내부에서 그들을 변경할 수 없습니다.
global 라인이 필요합니다. 거의 절대 그것에 도달하지 마세요: 값에서 전달하고, 결과에서 돌려받으면 함수가 따라가기 단순하게 유지됩니다. def calculate():
result = 42 # 이 함수에 로컬
return result
calculate()
print(result) # NameError, result는 여기에 존재하지 않음count = 0
def increment():
global count # 글로벌을 수정하고 싶다고 선언
count += 1
increment()
print(count) # 1global을 사용하는 것은 마지막 수단이어야 합니다. 그것은 코드를 이해하기 더 어렵게 만듭니다. 값을 전달하고 반환하는 것을 선호합니다. 스코프는 변수와 타입 챕터에서 다룬 할당이 이름을 값에 바인드하는 방법에서 직접 빌드합니다.
*args와 **kwargs
가끔 함수가 받을 인수의 개수를 모르면 어떻게 될까요. *args는 임의의 개수의 위치 인수를 튜플로 수집합니다. **kwargs는 임의의 개수의 키워드 인수를 딕셔너리로 수집합니다. args와 kwargs 이름은 관례이며, 별은 중요합니다.
def total(*args):
return sum(args)
total(1, 2, 3) # 6
total(1, 2, 3, 4, 5) # 15def display(**kwargs):
for key, value in kwargs.items():
print(f"{key}: {value}")
display(name="민지", score=87, level=5)이들을 일반 매개변수와 섞을 수 있습니다. 일반 매개변수가 먼저 옵니다:
def describe(title, *tags, **metadata):
print(f"{title} | tags: {tags} | meta: {metadata}")
describe("Python intro", "beginner", "python", author="민지", year=2024)*args는 추가 위치 인수의 임의 개수를 튜플로 퍼담고, **kwargs는 추가된 이름 붙은 것들을 딕셔너리로 퍼담습니다. args와 kwargs 단어는 관례일 뿐이며, `*`와 `**`은 실제 일을 합니다. 얼마나 많은 것이 들어오는지 미리 말할 수 없을 때 편리합니다. 문자열 표현
문자열 표현은 함수 맨 위의 문자열로, 그것이 무엇을 하는지 설명합니다. Python 에디터와 도구는 그것을 사용하여 함수 호출을 호버할 때 도움말을 보여줍니다. 삼중 따옴표를 사용하고, 단순 함수는 한 줄을 작성합니다.
def normalise(value, min_val, max_val):
"""값을 알려진 최소값과 최대값을 감안하여 0-1 범위로 스케일합니다."""
return (value - min_val) / (max_val - min_val)def build_url(base, version, resource, *, secure=True):
"""
API 엔드포인트 URL을 빌드합니다.
완전히 정규화된 URL 문자열을 반환합니다. secure이 False이면,
URL은 https 대신 http를 사용합니다.
"""
scheme = "https" if secure else "http"
base = base.replace("https://", "").replace("http://", "")
return f"{scheme}://{base}/{version}/{resource}"목적이 이름과 시그니처에서 명확하지 않은 모든 함수에 대해 문자열 표현을 작성하세요.
타입 힌트
타입 힌트를 사용하면 함수가 기대하고 반환하는 타입을 어노테이션할 수 있습니다. Python은 런타임에 그것들을 강제하지 않지만, 에디터는 아무것도 실행하기 전에 실수를 잡기 위해 그것들을 사용합니다. ->는 콜론 앞의 반환 타입을 지정합니다.
def greet(name: str, score: int) -> str:
return f"{name} scored {score}"def log(message: str) -> None:
print(f"[LOG] {message}")def top_scores(scores: list[int], n: int) -> list[int]:
return sorted(scores, reverse=True)[:n]타입 힌트는 선택입니다만 여러 장소에서 호출되는 모든 함수에 가치가 있습니다. 그들은 도구가 확인할 수 있는 문서입니다.
값으로서의 함수
Python의 함수는 문자열이나 숫자처럼 값입니다. 그들을 변수에 할당하고 다른 함수에 전달할 수 있습니다. 이것이 sorted()가 key= 함수를 받아들이는 방법입니다.
def double(x):
return x * 2
def apply(func, value):
return func(value)
apply(double, 5) # 10함수를 인수로 전달하는 것은 sorted(), map() 및 filter()로 지속적으로 나타납니다. 그리고 람다와 이해 챕터에서도 그것을 볼 것입니다.
실제로
함께 작동하는 두 함수: letter_grade는 점수를 글자로 변환하고, summarise는 리스트의 모든 점수에 대해 그것을 호출합니다:
def letter_grade(score: int) -> str:
if score >= 90:
return "A"
elif score >= 80:
return "B"
elif score >= 70:
return "C"
else:
return "F"
def summarise(scores: list[int]) -> None:
total = sum(scores)
avg = total / len(scores)
grades = []
for s in scores:
grades.append(letter_grade(s))
print(f"Average: {avg:.1f}")
print(f"Grades: {', '.join(grades)}")
summarise([87, 92, 74, 65, 91])