딕셔너리
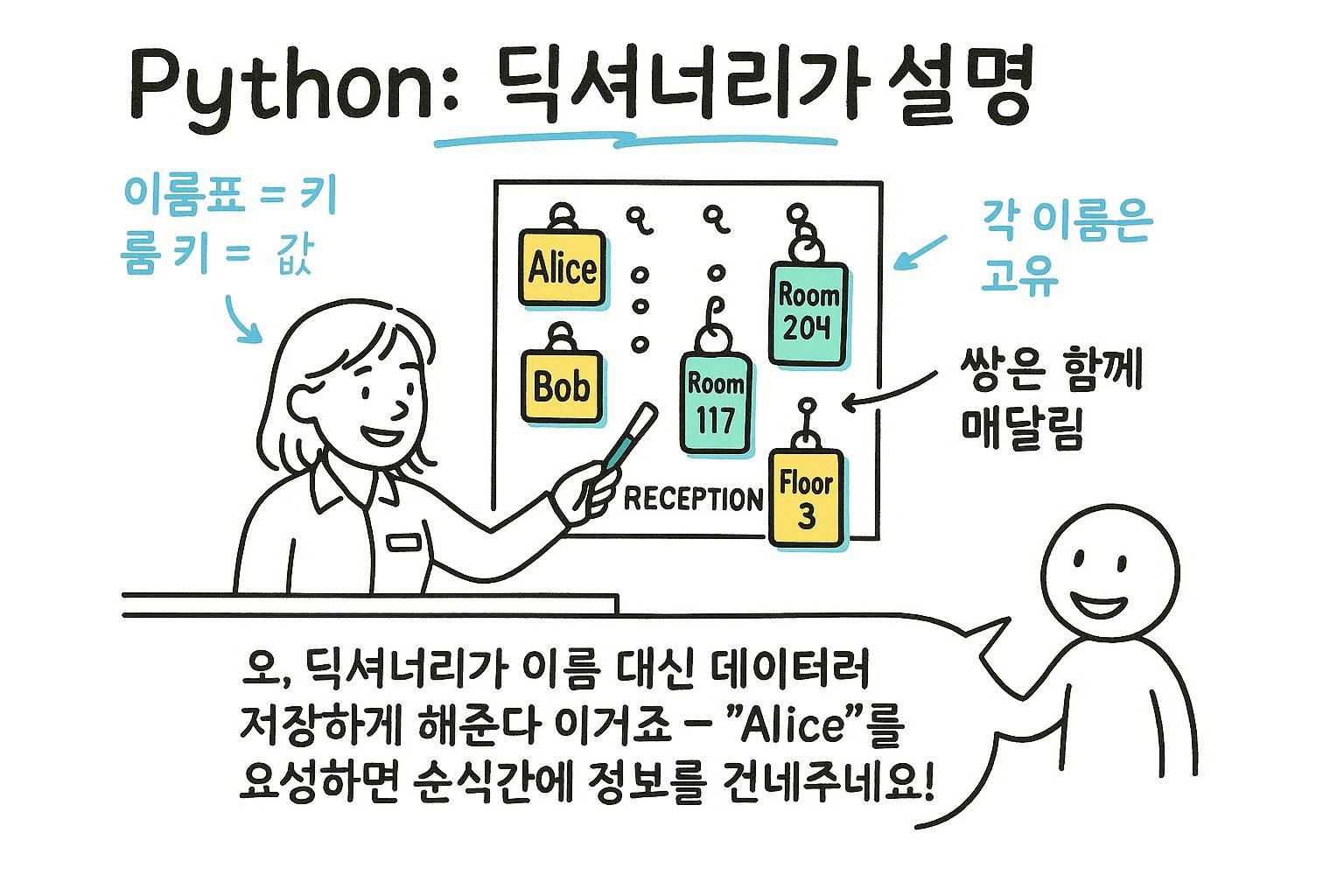
리스트를 사용하면 위치로 항목을 찾을 수 있습니다. 하지만 이름으로 항목을 찾고 싶을 때가 많습니다. "3번 항목을 주세요"가 아니라 "민지의 점수를 주세요"라고 하고 싶을 때죠. 딕셔너리는 데이터를 키-값 쌍으로 저장합니다. 위치가 아니라 키로 값을 찾습니다.
딕셔너리 생성
중괄호 안에 각 키와 값 사이에 콜론, 쌍 사이에 쉼표를 넣습니다. 키는 거의 항상 문자열입니다. 값은 무엇이든 될 수 있습니다. 숫자, 문자열, 다른 리스트, 심지어 다른 딕셔너리도 가능합니다.
player = {
"name": "민지",
"score": 87,
"level": 5,
"alive": True,
}
값 접근
대괄호 안에 키를 넣어서 값을 얻습니다. 키가 없으면 Python은 KeyError를 발생시킵니다. 키가 있는지 확실하지 않을 때는 .get()을 사용하세요. 충돌하는 대신 None을 반환하거나 지정한 기본값을 반환합니다.
player = {"name": "민지", "score": 87}
player["name"] # "민지"
player["score"] # 87
player["lives"] # KeyError (키가 없음)player.get("score") # 87
player.get("lives") # None (오류 없음, 기본값으로 None 반환)
player.get("lives", 3) # 3 (키가 없으면 이 기본값 사용).get()은 키가 없을 수 있을 때 더 안전합니다:
count = inventory.get("arrows", 0) # "arrows"가 딕셔너리에 없으면 0d["key"]는 값을 주지만, 그 키가 없으면 KeyError를 발생시킵니다. 확실하지 않을 때는 .get()을 사용하세요. 충돌하는 대신 None을 반환하거나, 넘긴 기본값을 반환합니다. 저는 이제 모든 것을 기본값으로 설정하고 누락된 키로 인한 프로그램 충돌이 없어졌습니다. 추가 및 업데이트
대괄호로 키에 할당합니다. 키가 이미 있으면 값이 바뀝니다. 없으면 새 항목이 생성됩니다. .update()를 사용하여 전체 다른 딕셔너리를 한 번에 병합합니다.
player = {"name": "민지", "score": 87}
player["score"] = 92 # 기존 항목 업데이트
player["level"] = 5 # 새 키 추가extras = {"level": 5, "alive": True}
player.update(extras) # extras의 키로 추가/덮어쓰기항목 제거
네 가지 제거 방법이 있습니다. .pop()은 키를 제거하고 값을 반환합니다. 기본값이 있는 .pop()은 키가 없을 수 있을 때 안전합니다. del은 반환값 없이 키를 제거합니다. .clear()는 전체 딕셔너리를 비웁니다.
player = {"name": "민지", "score": 87, "level": 5}
player.pop("level") # "level"을 제거하고 5를 반환
player.pop("lives", None) # 안전한 pop, 키가 없으면 None 반환
del player["score"] # "score"를 제거, 반환값 없음
player.clear() # 모두 제거.pop()에 기본값을 사용하는 것이 없을 수 있는 키를 제거하는 가장 안전한 방법입니다.
.pop(key)는 키를 제거하고 값을 반환하며, .pop(key, None)은 키가 없을 수 있을 때 침착합니다. del d[key]는 반환값 없이 제거하고, .clear()는 전부 비웁니다. .pop()의 기본값이 많은 `KeyError` 놀라움으로부터 저를 구했습니다. 반복
세 가지 뷰로 딕셔너리의 다른 부분을 반복할 수 있습니다. 딕셔너리를 직접 반복하면 키를 얻습니다. .values()는 값을 줍니다. .items()는 둘 다 한 번에 주며, 이것이 가장 많이 사용할 것입니다. 각 쌍을 두 이름으로 분해하여 깔끔하고 읽기 좋은 루프를 만드세요.
player = {"name": "민지", "score": 87, "level": 5}
for key in player: # 키 반복 (가장 흔함)
print(key)
for key in player.keys(): # 같음, 명시적 키 뷰
print(key)
for value in player.values(): # 값들
print(value)
for key, value in player.items(): # 둘 다, 가장 유용함
print(f"{key}: {value}").items()가 가장 많이 사용할 것입니다. 각 쌍을 두 이름으로 분해하면 루프가 읽기 좋아집니다.
.values()는 값을 주고, .items()는 둘 다 주며, 이것이 가장 많이 사용할 것입니다. 각 쌍을 `for key, value in player.items()`처럼 두 이름으로 분해하면 루프가 훨씬 읽기 좋아졌습니다. 멤버십 확인
in은 딕셔너리에 키가 있는지 확인합니다. 값을 확인하지 않고 키만 확인합니다. 무언가가 없는지 확인하려면 not in을 사용하세요.
player = {"name": "민지", "score": 87}
"name" in player # True
"lives" in player # False
"lives" not in player # Truein은 키만 확인합니다. 값을 확인하려면 in player.values()를 사용하면 되지만, 거의 필요하지 않습니다.
in은 키가 딕셔너리에 있는지 말해주며, 오직 키만입니다. 딕셔너리가 아무리 커도 빠릅니다. not in으로 뒤집어 무언가가 없는지 확인하세요. 중첩 딕셔너리
값은 그 자체로 딕셔너리일 수 있습니다. 이렇게 여러 수준의 구조화된 데이터를 표현합니다. 플레이어가 스탯 섹션을 가지거나, 설정 파일이 서브 섹션을 가질 때입니다. 중첩된 값에 대괄호 두 개로 접근합니다. 첫 번째는 외부 키를 선택하고, 두 번째는 내부 키를 선택합니다.
users = {
"alice": {"score": 87, "level": 5},
"bob": {"score": 74, "level": 3},
}
users["alice"]["score"] # 87
users["bob"]["level"] # 3연결된 대괄호로 접근합니다. 깊게 중첩된 구조의 경우 이것이 번거로워질 수 있으므로 가능하면 중첩을 얕게 유지하세요.
setdefault
.setdefault()는 키가 있으면 읽고, 없으면 기본값으로 설정한 후 값을 반환합니다. 키가 존재하길 원하지만 이미 있으면 덮어쓰고 싶지 않을 때 유용합니다.
inventory = {}
inventory.setdefault("arrows", 0) # "arrows": 0를 설정하고, 0을 반환
inventory.setdefault("arrows", 10) # "arrows"가 이미 있으므로 변경 없음, 0 반환키 존재를 먼저 확인하지 않고 그룹화된 구조를 구축하는 데 유용합니다:
groups = {}
for name, team in players:
groups.setdefault(team, []).append(name).setdefault(key, default)는 키가 있으면 읽고, 없으면 기본값으로 설정하고 반환합니다. 이미 있는 값을 망치지 않고 키가 존재하는지 확인하는 깔끔한 방법입니다. 저는 대부분 그룹화에 사용하며, "이 키가 여기 있나요?" 확인이 필요 없습니다. collections.defaultdict 및 Counter
표준 라이브러리에는 일반적인 패턴을 자동으로 처리하는 두 가지 딕셔너리 서브클래스가 있습니다. defaultdict는 누락된 키에 대해 기본값을 만들므로 KeyError를 절대 얻지 못합니다. Counter는 시퀀스에서 각 항목이 나타나는 빈도를 세고 결과를 딕셔너리로 제공합니다.
defaultdict와 Counter는 표준 라이브러리에 있으므로 먼저 가져와야 합니다. 가져오기는 모듈 장에서 완전히 다룹니다.
from collections import defaultdict
groups = defaultdict(list)
for name, team in players:
groups[team].append(name) # 팀이 새로우면 KeyError 없음from collections import Counter
words = ["cat", "dog", "cat", "bird", "cat", "dog"]
counts = Counter(words)
# Counter({'cat': 3, 'dog': 2, 'bird': 1})
counts.most_common(2) # [('cat', 3), ('dog', 2)]Counter는 많은 "루프에서 것을 센다" 보일러플레이트를 절약합니다.
defaultdict는 누락된 키에 대해 기본값을 채우므로 그룹화와 계산이 더 이상 `KeyError`를 던지지 않습니다. Counter는 시퀀스에서 각 항목이 얼마나 자주 나타나는지 세고 딕셔너리로 반환합니다. 처음 손으로 쓴 계산 루프를 `Counter`로 바꿨을 때, 제 코드의 절반이 사라졌습니다. 실제 사용
점수 추적 도구를 구축하고 모든 항목이 포함된 요약을 인쇄합니다:
scores = {"민지": 87, "준호": 74, "예은": 92, "경준": 55}
total = sum(scores.values())
average = total / len(scores)
print(f"플레이어: {len(scores)}")
print(f"평균: {average:.1f}")
print(f"최고: {max(scores.values())}")
print(f"최저: {min(scores.values())}")
print()
for name, score in scores.items():
print(f" {name}: {score}")