शब्दकोश
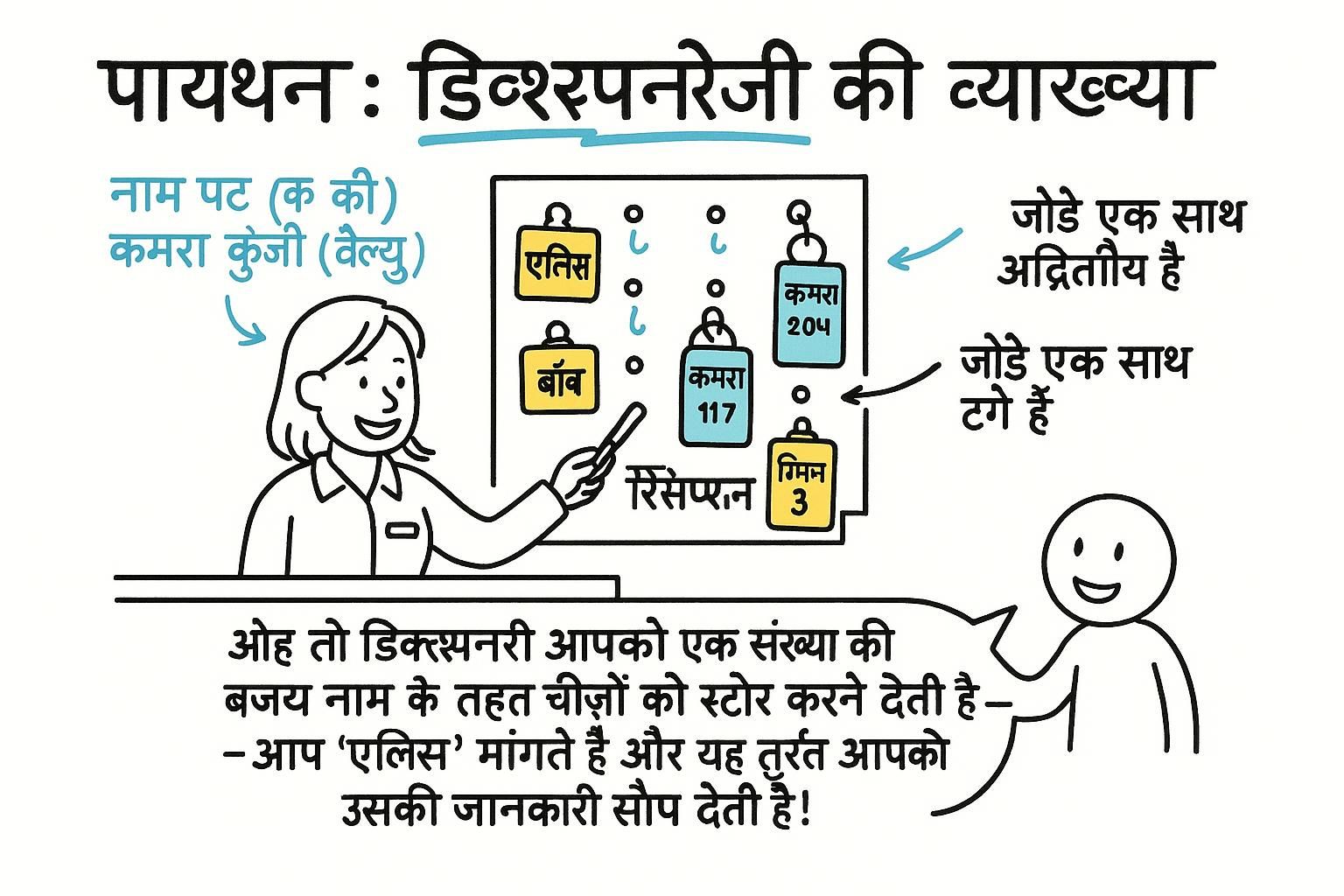
लिस्ट आपको स्थिति के आधार पर चीजें देखने देते हैं। लेकिन अक्सर आप किसी चीज को नाम से देखना चाहते हैं। "मुझे item 3 दो" नहीं, बल्कि "मुझे राज का स्कोर दो"। एक शब्दकोश डेटा को key-value जोड़े के रूप में संग्रहीत करता है: आप किसी मान को स्थिति के बजाय इसकी key से देखते हैं।
एक शब्दकोश बनाना
घुंघराले ब्रेसिज़ एक colon के साथ प्रत्येक key और value के बीच, और जोड़े के बीच commas। Keys लगभग हमेशा strings होती हैं। Values कुछ भी हो सकता है: संख्याएं, strings, अन्य lists, यहां तक कि अन्य शब्दकोश।
# खिलाड़ी
player = {
"name": "राज",
"score": 87,
"level": 5,
"alive": True,
}
मान एक्सेस करना
key के साथ square brackets का उपयोग करके value पाएं। यदि key मौजूद नहीं है, तो Python एक KeyError raise करता है। .get() का उपयोग करें जब आप सुनिश्चित नहीं हैं कि key वहां है: यह None return करता है crash के बजाय, या एक default value जो आप specify करते हैं।
player = {"name": "राज", "score": 87}
player["name"] # "राज"
player["score"] # 87
player["lives"] # KeyError (key doesn't exist)player.get("score") # 87
player.get("lives") # None (no error, returns None by default)
player.get("lives", 3) # 3 (use this default if key is absent).get() ज्यादा safe है जब भी key missing हो सकती है:
count = inventory.get("arrows", 0) # 0 if "arrows" isn't in the dictd["key"] आपको value देता है, लेकिन `KeyError` raise करता है अगर वह key नहीं है। जब आप निश्चित नहीं हैं, तो .get() के लिए पहुंचें: यह `None` return करता है crash के बजाय, या एक default जो आप pass करते हैं। मैं अब सब कुछ default करता हूं और मेरे programs missing keys पर crashing बंद कर गए। जोड़ना और अपडेट करना
Square brackets के साथ एक key को assign करें। यदि key पहले से exists करती है, तो value replace हो जाता है। यदि यह अभी तक मौजूद नहीं है, तो एक नई entry बनाई जाती है। .update() का उपयोग करके एक पूरे अन्य शब्दकोश को एक साथ merge करें।
player = {"name": "राज", "score": 87}
player["score"] = 92 # update existing
player["level"] = 5 # add new keyextras = {"level": 5, "alive": True}
player.update(extras) # adds/overwrites with keys from extrasआइटम हटाना
हटाने के चार तरीके हैं। .pop() एक key को हटाता है और आपको value वापस देता है। .pop() एक default के साथ safe है जब key नहीं हो सकती है। del एक key को return value के बिना हटाता है। .clear() पूरे शब्दकोश को empty करता है।
player = {"name": "राज", "score": 87, "level": 5}
player.pop("level") # removes "level" and returns 5
player.pop("lives", None) # safe pop, returns None if key absent
del player["score"] # removes "score", no return value
player.clear() # removes everything.pop() एक default के साथ key को remove करने का safest तरीका है जो नहीं हो सकती है।
.pop(key) एक key को हटाता है और आपको इसकी value वापस देता है, और .pop(key, None) शांत रहता है जब key नहीं हो सकती है। del d[key] कुछ return किए बिना hटाता है, .clear() बाकी को empty करता है। .pop() पर default ने मुझे `KeyError` surprises से बहुत सारे बचाए हैं। पुनरावृति
तीन views आपको एक dictionary के विभिन्न भागों के through loop करने देते हैं। Dict को सीधे iterate करना आपको keys देता है। .values() values देता है। .items() दोनों एक बार में देता है और यह है जो आप most का use करेंगे: प्रत्येक pair को clean, readable loops के लिए दो names में unpack करें।
player = {"name": "राज", "score": 87, "level": 5}
for key in player: # iterate keys (most common)
print(key)
for key in player.keys(): # same, explicit keys view
print(key)
for value in player.values(): # the values
print(value)
for key, value in player.items(): # both, most useful
print(f"{key}: {value}").items() है जो आप most का use करेंगे। प्रत्येक pair को दो names में unpack करना loop को readable बनाता है।
.values() values देता है, और .items() दोनों एक बार में देता है, जो है जिसके लिए आप most reach करेंगे। प्रत्येक pair को दो names में unpack करना जैसे for key, value in player.items() मेरे loops को बहुत easier बनाने के लिए read करना। सदस्यता जांचना
in checks करता है कि क्या एक key dictionary में exists करती है। यह values को check नहीं करता, केवल keys को। checking करने के लिए कि क्या कुछ present नहीं है, not in का उपयोग करें।
player = {"name": "राज", "score": 87}
"name" in player # True
"lives" in player # False
"lives" not in player # Truein केवल keys को check करता है। values को check करने के लिए, in player.values() का उपयोग करें, हालांकि यह rarely आवश्यक है।
in बताता है कि क्या key dict में है, और केवल एक key, कभी value नहीं। यह fast stays करता है कोई बात नहीं dict कितना बड़ा हो जाता है। इसे not in को flip करें यह check करने के लिए कि क्या कुछ absent है। नेस्टेड शब्दकोश
Values खुद को शब्दकोश हो सकते हैं। यही है कैसे आप structured data को multiple levels के साथ represent करते हैं: एक player जो एक stats section है, एक config file sub-sections के साथ। दो sets of square brackets एक nested value को access करते हैं: पहला outer key को pick करता है, दूसरा inner key को pick करता है।
users = {
"राज": {"score": 87, "level": 5},
"प्रिया": {"score": 74, "level": 3},
}
users["राज"]["score"] # 87
users["प्रिया"]["level"] # 3chained square brackets के साथ access करें। deeply nested structures के लिए, यह unwieldy बन सकता है, इसलिए जहां आप कर सकें वहां nesting को shallow रखें।
setdefault
.setdefault() एक key को read करता है यदि यह exists करता है, या इसे एक default value को set करता है यदि यह नहीं करता है, फिर value को return करता है। यह useful है जब आपको एक key को exist करने की जरूरत है लेकिन आप इसे overwrite नहीं करना चाहते यदि यह पहले से है।
inventory = {}
inventory.setdefault("arrows", 0) # sets "arrows": 0, returns 0
inventory.setdefault("arrows", 10) # "arrows" already exists, no change, returns 0यह useful है grouped structures को बिना पहले key existence को check किए build करने के लिए:
groups = {}
for name, team in players:
groups.setdefault(team, []).append(name).setdefault(key, default) एक key को read करता है यदि यह है, या यदि यह नहीं है तो इसे default को set करता है और return करता है। यह tidy तरीका है एक key को make sure करने का exists बिना एक value को clobber किए जो पहले से है। मैं इसे most use करता हूं grouping के लिए, "is this key here yet?" check की जरूरत नहीं है। collections.defaultdict और Counter
standard library के दो dict subclasses हैं जो common patterns को automatically handle करते हैं। defaultdict एक default value को missing keys के लिए create करता है इसलिए आपको कभी KeyError नहीं मिलता है। Counter count करता है कि कितनी बार प्रत्येक item एक sequence में दिखाई देता है और आपको results को एक dict के रूप में देता है।
defaultdict और Counter standard library में live हैं, इसलिए उन्हें पहले importing की जरूरत है। Imports को full treatment मिलता है Modules अध्याय में।
from collections import defaultdict
groups = defaultdict(list)
for name, team in players:
groups[team].append(name) # no KeyError if team is newfrom collections import Counter
words = ["cat", "dog", "cat", "bird", "cat", "dog"]
counts = Counter(words)
# Counter({'cat': 3, 'dog': 2, 'bird': 1})
counts.most_common(2) # [('cat', 3), ('dog', 2)]Counter बहुत सारे "count things in a loop" boilerplate को saves करता है।
defaultdict किसी भी missing key के लिए एक default को fill करता है, इसलिए grouping और counting को `KeyError` throw करना बंद करता है। Counter tally करता है कि कितनी बार प्रत्येक item एक sequence में shows होता है और इसे dict के रूप में hand करता है। पहली बार मैंने एक hand-written counting loop को `Counter` के लिए swap किया, आधा मेरा code disappear हो गया। व्यवहार में
एक score tracker को building करना और एक summary को सभी entries के साथ print करना:
# सभी स्कोर
scores = {"राज": 87, "प्रिया": 74, "कार्तिक": 92, "दीक्षा": 55}
total = sum(scores.values())
average = total / len(scores)
print(f"खिलाड़ी: {len(scores)}")
print(f"औसत: {average:.1f}")
print(f"सर्वोच्च: {max(scores.values())}")
print(f"न्यूनतम: {min(scores.values())}")
print()
for name, score in scores.items():
print(f" {name}: {score}")