Diccionarios
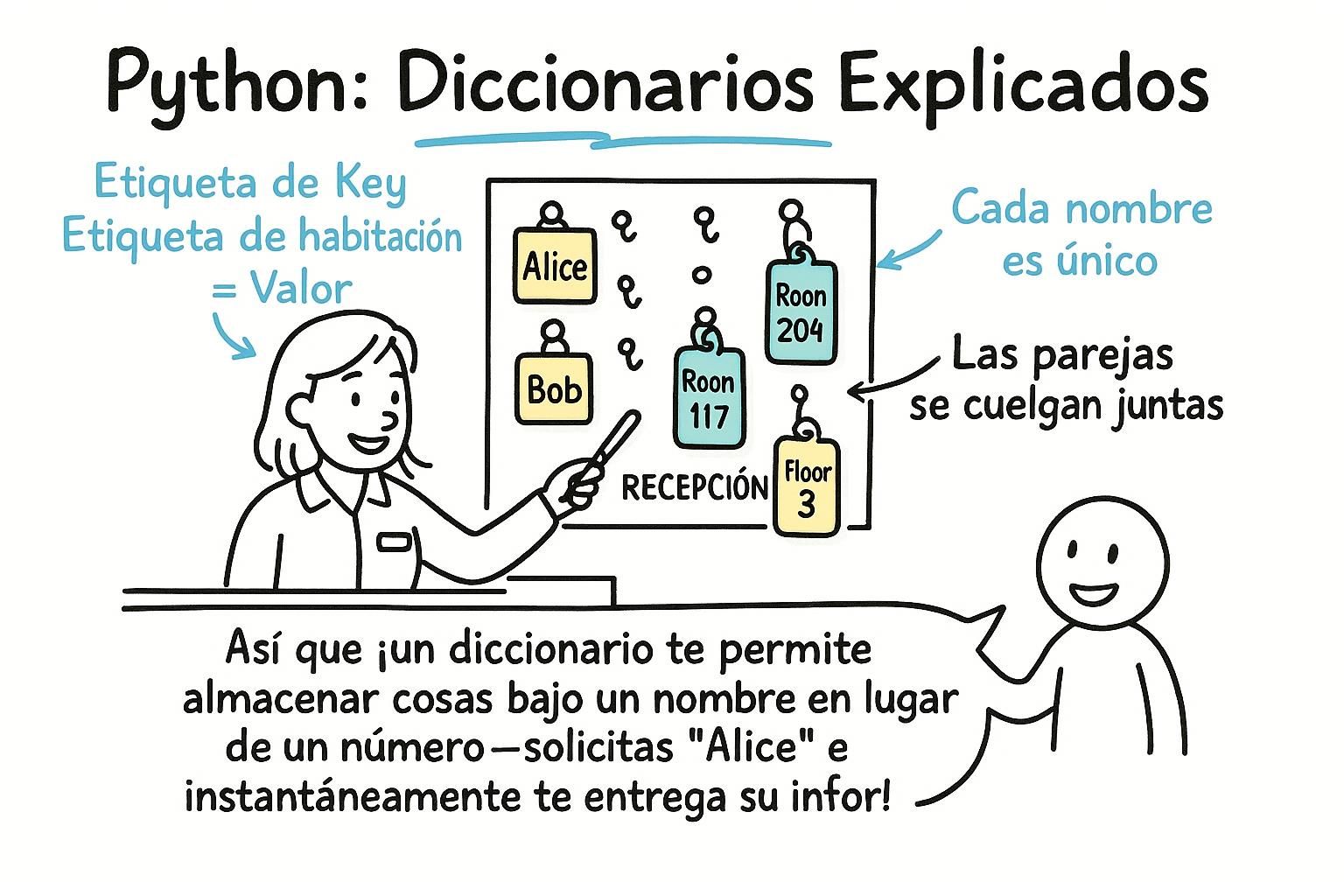
Las listas te permiten buscar cosas por posición. Pero a menudo quieres buscar algo por nombre. No "dame el elemento 3", sino "dame la puntuación de María". Un diccionario almacena datos como pares clave-valor: buscas un valor por su clave, no por su posición.
Crear un diccionario
Llaves con un dos puntos entre cada clave y valor, y comas entre pares. Las claves son casi siempre strings. Los valores pueden ser cualquier cosa: números, strings, otras listas, incluso otros diccionarios.
player = {
"name": "María",
"score": 87,
"level": 5,
"alive": True,
}
Acceder a valores
Usa corchetes con la clave para obtener el valor. Si la clave no existe, Python lanza un KeyError. Usa .get() cuando no estés seguro de que una clave esté allí: devuelve None en lugar de fallar, o un valor por defecto que especifiques.
player = {"name": "María", "score": 87}
player["name"] # "María"
player["score"] # 87
player["lives"] # KeyError (clave no existe)player.get("score") # 87
player.get("lives") # None (sin error, devuelve None por defecto)
player.get("lives", 3) # 3 (usa este valor por defecto si la clave no existe).get() es más seguro cada vez que una clave podría faltar:
count = inventory.get("arrows", 0) # 0 si "arrows" no está en el diccionariod["clave"] te da el valor, pero lanza KeyError si esa clave no está allí. Cuando no estés seguro, usa .get(): devuelve None en lugar de fallar, o un valor por defecto que pases. Ahora establezco valores por defecto en todo y mis programas dejaron de fallar en claves faltantes. Añadir y actualizar
Asigna a una clave con corchetes. Si la clave ya existe, el valor se reemplaza. Si aún no existe, se crea una nueva entrada. Usa .update() para fusionar un diccionario completo de una sola vez.
player = {"name": "María", "score": 87}
player["score"] = 92 # actualizar existente
player["level"] = 5 # añadir nueva claveextras = {"level": 5, "alive": True}
player.update(extras) # añade/sobrescribe con claves de extras.update() para incorporar un diccionario completo de una sola vez. Eliminar elementos
Cuatro formas de eliminar entradas. .pop() elimina una clave y te devuelve el valor. .pop() con un valor por defecto es seguro cuando la clave podría no estar allí. del elimina una clave sin devolver nada. .clear() vacía el diccionario completo.
player = {"name": "María", "score": 87, "level": 5}
player.pop("level") # elimina "level" y devuelve 5
player.pop("lives", None) # pop seguro, devuelve None si la clave no existe
del player["score"] # elimina "score", sin valor devuelto
player.clear() # elimina todo.pop() con un valor por defecto es la forma más segura de eliminar una clave que podría no existir.
.pop(clave) elimina una clave y te devuelve su valor, y .pop(clave, None) se mantiene tranquilo cuando la clave podría no estar allí. del d[clave] elimina sin devolver nada, .clear() vacía todo. El valor por defecto en .pop() me salvó de muchas sorpresas de KeyError. Iterar
Tres vistas te permiten iterar a través de diferentes partes de un diccionario. Iterar el diccionario directamente te da las claves. .values() te da los valores. .items() te da ambas a la vez y es lo que usarás más: desempaqueta cada par en dos nombres para bucles limpios y legibles.
player = {"name": "María", "score": 87, "level": 5}
for key in player: # iterar claves (más común)
print(key)
for key in player.keys(): # igual, vista de claves explícita
print(key)
for value in player.values(): # los valores
print(value)
for key, value in player.items(): # ambas, más útil
print(f"{key}: {value}").items() es lo que usarás más. Desempaquetar cada par en dos nombres hace el bucle legible.
.values() te da los valores, e .items() te da ambas a la vez, que es la que usarás más. Desempaquetar cada par en dos nombres como for clave, valor in player.items() hizo mis bucles mucho más fáciles de leer. Verificar membresía
in verifica si una clave existe en el diccionario. No verifica valores, solo claves. Para verificar si algo no está presente, usa not in.
player = {"name": "María", "score": 87}
"name" in player # True
"lives" in player # False
"lives" not in player # Truein solo verifica claves. Para verificar valores, usa in player.values(), aunque eso raramente es necesario.
in te dice si una clave está en el diccionario, y solo una clave, nunca un valor. Se mantiene rápido sin importar cuán grande sea el diccionario. Cámbialo a not in para verificar que algo está ausente. Diccionarios anidados
Los valores pueden ser diccionarios en sí mismos. Así es cómo representas datos estructurados con múltiples niveles: un jugador que tiene una sección de estadísticas, un archivo de configuración con subsecciones. Dos conjuntos de corchetes acceden a un valor anidado: el primero elige la clave externa, el segundo elige la clave interna.
users = {
"maria": {"score": 87, "level": 5},
"juan": {"score": 74, "level": 3},
}
users["maria"]["score"] # 87
users["juan"]["level"] # 3Accede con corchetes encadenados. Para estructuras profundamente anidadas, esto puede volverse engorroso, así que mantén la anidación poco profunda donde puedas.
setdefault
.setdefault() lee una clave si existe, o la establece en un valor por defecto si no existe, y luego devuelve el valor. Es útil cuando necesitas que una clave exista pero no quieres sobrescribirla si ya está allí.
inventory = {}
inventory.setdefault("arrows", 0) # establece "arrows": 0, devuelve 0
inventory.setdefault("arrows", 10) # "arrows" ya existe, sin cambios, devuelve 0Es útil para construir estructuras agrupadas sin verificar la existencia de la clave primero:
groups = {}
for name, team in players:
groups.setdefault(team, []).append(name).setdefault(clave, default) lee una clave si está allí, o la establece en el valor por defecto y la devuelve si no está. Es la forma ordenada de asegurarse de que una clave existe sin clobbear un valor que ya está dentro. La uso más para agrupar cosas, sin necesidad de verificar "¿está esta clave aquí aún?". collections.defaultdict y Counter
La biblioteca estándar tiene dos subclases de diccionario que manejan patrones comunes automáticamente. defaultdict crea un valor por defecto para claves faltantes para que nunca obtengas un KeyError. Counter cuenta cuántas veces aparece cada elemento en una secuencia y te da los resultados como un diccionario.
defaultdict y Counter viven en la biblioteca estándar, así que necesitan ser importadas primero. Las importaciones reciben tratamiento completo en el capítulo Módulos.
from collections import defaultdict
groups = defaultdict(list)
for name, team in players:
groups[team].append(name) # sin KeyError si team es nuevofrom collections import Counter
words = ["cat", "dog", "cat", "bird", "cat", "dog"]
counts = Counter(words)
# Counter({'cat': 3, 'dog': 2, 'bird': 1})
counts.most_common(2) # [('cat', 3), ('dog', 2)]Counter ahorra mucho boilerplate de "contar cosas en un bucle".
defaultdict proporciona un valor por defecto para cualquier clave faltante, así que agrupar y contar dejan de lanzarte KeyError. Counter cuenta cuántas veces aparece cada elemento en una secuencia y te lo devuelve como un diccionario. La primera vez que cambié un bucle de conteo escrito a mano por Counter, la mitad de mi código desapareció. En la práctica
Construir un rastreador de puntuación e imprimir un resumen con todas las entradas:
scores = {"María": 87, "Juan": 74, "Carol": 92, "David": 55}
total = sum(scores.values())
average = total / len(scores)
print(f"Jugadores: {len(scores)}")
print(f"Promedio: {average:.1f}")
print(f"Más alto: {max(scores.values())}")
print(f"Más bajo: {min(scores.values())}")
print()
for name, score in scores.items():
print(f" {name}: {score}")