辞書
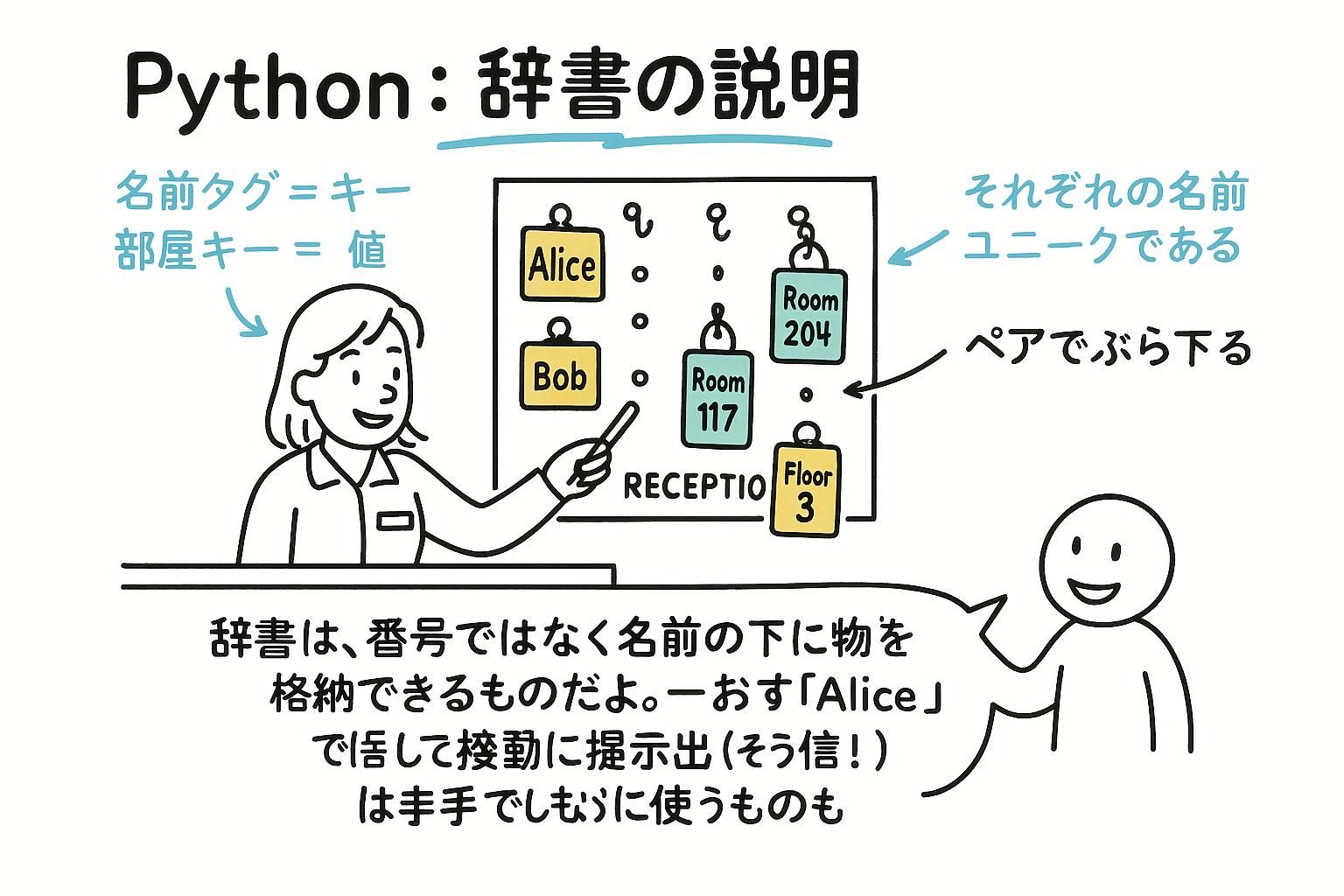
リストは位置で項目を検索できます。しかし、多くの場合は名前で検索したいものです。「3番目の項目をくれ」ではなく、「太郎のスコアをくれ」といった感じです。辞書はキー値ペアとしてデータを保存します。位置ではなく、キーで値を検索します。
辞書の作成
各キーと値の間にコロンがある波括弧で、ペア間にコンマがあります。キーはほぼ常に文字列です。値は何でもできます:数値、文字列、他のリスト、さらに他の辞書。
player = {
"name": "太郎",
"score": 87,
"level": 5,
"alive": True,
}
値へのアクセス
キーを持つ角括弧を使って値を取得します。キーが存在しない場合、PythonはKeyErrorを発生させます。キーがそこにあるかどうか確信がない場合は、.get()を使用してください:クラッシュする代わりにNoneを返します、または指定したデフォルト値を返します。
player = {"name": "太郎", "score": 87}
player["name"] # "太郎"
player["score"] # 87
player["lives"] # KeyError (キーが存在しない)player.get("score") # 87
player.get("lives") # None (エラーなし、デフォルトではNoneを返す)
player.get("lives", 3) # 3 (キーが無い場合はこのデフォルトを使用).get()はキーが見つからない可能性がある場合に安全です:
count = inventory.get("arrows", 0) # 辞書に"arrows"がない場合は0d["key"]は値を渡しますが、そのキーがない場合はKeyErrorを発生させます。確実でない場合は、.get()に手を伸ばします。クラッシュする代わりにNoneを返すか、渡したデフォルトを返します。今はすべてをデフォルトにしており、プログラムは見つからないキーでのクラッシュをやめました。 追加と更新
角括弧を使ってキーに割り当てます。キーが既に存在する場合、値は置き換えられます。まだ存在しない場合、新しいエントリが作成されます。.update()を使用して、別の辞書全体を一度にマージします。
player = {"name": "太郎", "score": 87}
player["score"] = 92 # 既存のものを更新
player["level"] = 5 # 新しいキーを追加extras = {"level": 5, "alive": True}
player.update(extras) # extrasのキーで追加/上書き.update()を使用してください。 アイテムの削除
エントリを削除する4つの方法があります。.pop()はキーを削除して値を返します。デフォルト付きの.pop()は、キーが見つからない可能性がある場合に安全です。delはキーを削除して戻り値はありません。.clear()は辞書全体を空にします。
player = {"name": "太郎", "score": 87, "level": 5}
player.pop("level") # "level"を削除して5を返す
player.pop("lives", None) # 安全なpop、キー不在の場合はNoneを返す
del player["score"] # "score"を削除、戻り値なし
player.clear() # すべてを削除デフォルト付きの.pop()は、見つからない可能性があるキーを削除する最も安全な方法です。
.pop(key)はキーを削除して値を返します。.pop(key, None)はキーが見つからない可能性がある場合でも落ち着いています。del d[key]は何も返さずに削除します。.clear()はすべてを空にします。.pop()のデフォルトは、多くのKeyErrorの驚きから私を救いました。 反復処理
3つのビューで、辞書のさまざまな部分をループさせることができます。辞書を直接反復するとキーが得られます。.values()は値を与えます。.items()は両方を一度に与え、これが最も多く使用するものです。各ペアを2つの名前にアンパックして、きれいで読みやすいループを作成します。
player = {"name": "太郎", "score": 87, "level": 5}
for key in player: # キーを反復処理(最も一般的)
print(key)
for key in player.keys(): # 同じ、明示的なキービュー
print(key)
for value in player.values(): # 値
print(value)
for key, value in player.items(): # 両方、最も有用
print(f"{key}: {value}").items()が最も使用するものです。各ペアを2つの名前にアンパックするとループが読みやすくなります。
.values()は値を与えます。.items()は両方を与え、これが最も多く使用するものです。for key, value in player.items()のように各ペアを2つの名前にアンパックすることで、ループが非常に読みやすくなりました。 メンバーシップの確認
inは、キーが辞書に存在するかどうかをチェックします。値をチェックするのではなく、キーのみをチェックします。何かが存在しないかどうかをチェックするには、not inを使用してください。
player = {"name": "太郎", "score": 87}
"name" in player # True
"lives" in player # False
"lives" not in player # Trueinはキーのみをチェックします。値をチェックするには、in player.values()を使用します。ただし、これはめったに必要ありません。
inはキーが辞書にあるかどうかを示し、キーのみです。辞書がどのくらい大きくなっても速いままです。not inに反転して、何かが不在かどうかをチェックします。 ネストされた辞書
値は辞書そのものになることができます。これは、複数のレベルで構造化されたデータを表現する方法です。統計情報を持つプレイヤー、サブセクション付きの設定ファイル。2セットの角括弧がネストされた値にアクセスします。1つ目は外側のキーを選び、2つ目は内側のキーを選びます。
users = {
"太郎": {"score": 87, "level": 5},
"花子": {"score": 74, "level": 3},
}
users["太郎"]["score"] # 87
users["花子"]["level"] # 3チェーン連鎖された角括弧でアクセスします。深くネストされた構造の場合、これは厄介になる可能性があるため、可能な限りネストを浅く保つようにしてください。
setdefault
.setdefault()はキーが存在する場合は読み取り、存在しない場合はデフォルト値に設定します。その後、値を返します。キーが存在する必要があるが、既にある場合は上書きしたくない場合に便利です。
inventory = {}
inventory.setdefault("arrows", 0) # "arrows": 0を設定し、0を返す
inventory.setdefault("arrows", 10) # "arrows"は既に存在します。変更なし。0を返すキー存在を最初にチェックすることなく、グループ化された構造を構築するのに便利です:
groups = {}
for name, team in players:
groups.setdefault(team, []).append(name).setdefault(key, default)はキーが存在する場合は読み取り、そこにない場合はデフォルトに設定して返します。キーが存在することを確認する良い方法で、既にある値を消さないようにしてください。ほとんどの場合、物をグループ化するために使用します。「このキーがここにあるか」チェックは必要ありません。 collections.defaultdict とCounter
標準ライブラリには、一般的なパターンを自動的に処理する2つの辞書サブクラスがあります。defaultdictは見つからないキーのデフォルト値を作成するため、KeyErrorは発生しません。Counterは、シーケンス内の各アイテムが表示される頻度を数え、結果を辞書として提供します。
defaultdictとCounterは標準ライブラリに存在するため、最初にインポートする必要があります。インポートはモジュールの章で完全に扱われます。
from collections import defaultdict
groups = defaultdict(list)
for name, team in players:
groups[team].append(name) # チームが新しい場合、KeyErrorはなしfrom collections import Counter
words = ["cat", "dog", "cat", "bird", "cat", "dog"]
counts = Counter(words)
# Counter({'cat': 3, 'dog': 2, 'bird': 1})
counts.most_common(2) # [('cat', 3), ('dog', 2)]Counterは多くの「ループ内の物をカウント」のボイラープレートを保存します。
defaultdictは見つからないキーに対してデフォルトを埋めるため、グループ化とカウントは`KeyError`を投げなくなります。`Counter`は、シーケンス内の各アイテムが表示される頻度を数え、辞書として戻します。最初に手書きカウントループを`Counter`に交換したとき、コードの半分は消えました。 実践で
スコアトラッカーを構築し、すべてのエントリを含むサマリーを印刷します:
scores = {"太郎": 87, "花子": 74, "三郎": 92, "四郎": 55}
total = sum(scores.values())
average = total / len(scores)
print(f"プレイヤー数: {len(scores)}")
print(f"平均: {average:.1f}")
print(f"最高: {max(scores.values())}")
print(f"最低: {min(scores.values())}")
print()
for name, score in scores.items():
print(f" {name}: {score}")