Dictionaries
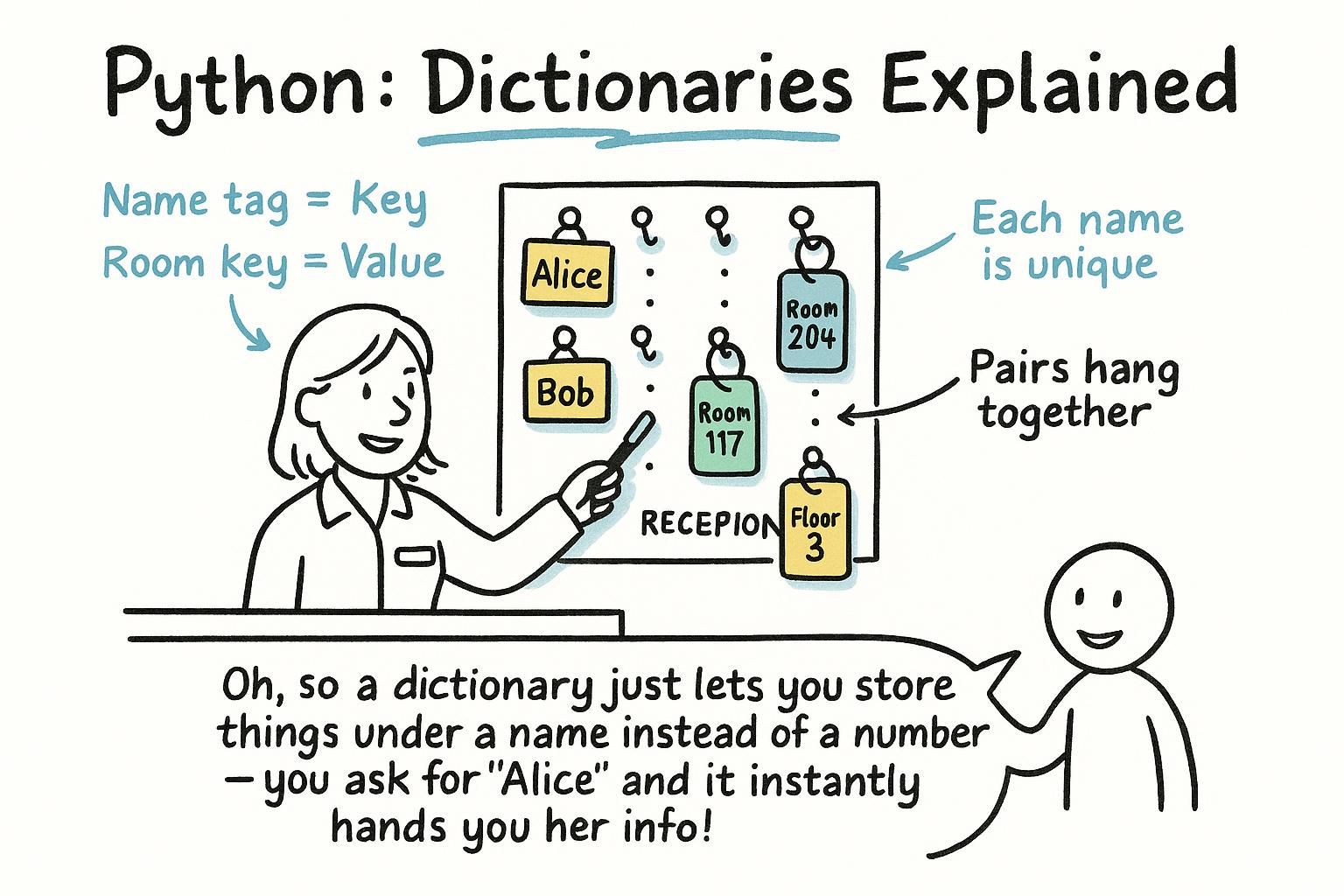
Lists let you look things up by position. But often you want to look something up by name. Not "give me item 3", but "give me the score for Alice". A dictionary stores data as key-value pairs: you look up a value by its key, not its position.
Creating a dictionary
Curly braces with a colon between each key and value, and commas between pairs. Keys are almost always strings. Values can be anything: numbers, strings, other lists, even other dictionaries.
player = {
"name": "Alice",
"score": 87,
"level": 5,
"alive": True,
}
Accessing values
Use square brackets with the key to get the value. If the key does not exist, Python raises a KeyError. Use .get() when you are not sure a key is there: it returns None instead of crashing, or a default value you specify.
player = {"name": "Alice", "score": 87}
player["name"] # "Alice"
player["score"] # 87
player["lives"] # KeyError (key doesn't exist)player.get("score") # 87
player.get("lives") # None (no error, returns None by default)
player.get("lives", 3) # 3 (use this default if key is absent).get() is safer whenever a key might be missing:
count = inventory.get("arrows", 0) # 0 if "arrows" isn't in the dictd["key"] hands you the value, but raises KeyError if that key isn't there. When you're not certain, reach for .get(): it returns None instead of crashing, or a default you pass in. I default-everything now and my programs stopped crashing on missing keys. Adding and updating
Assign to a key with square brackets. If the key already exists, the value is replaced. If it does not exist yet, a new entry is created. Use .update() to merge an entire other dictionary in at once.
player = {"name": "Alice", "score": 87}
player["score"] = 92 # update existing
player["level"] = 5 # add new keyextras = {"level": 5, "alive": True}
player.update(extras) # adds/overwrites with keys from extras.update() to fold an entire other dictionary in at once. Removing items
Four ways to remove entries. .pop() removes a key and gives you the value back. .pop() with a default is safe when the key might not be there. del removes a key with no return value. .clear() empties the whole dictionary.
player = {"name": "Alice", "score": 87, "level": 5}
player.pop("level") # removes "level" and returns 5
player.pop("lives", None) # safe pop, returns None if key absent
del player["score"] # removes "score", no return value
player.clear() # removes everything.pop() with a default is the safest way to remove a key that might not exist.
.pop(key) removes a key and hands you its value back, and .pop(key, None) stays calm when the key might not be there. del d[key] removes without returning anything, .clear() empties the lot. The default on .pop() saved me from a lot of KeyError surprises. Iterating
Three views let you loop through different parts of a dictionary. Iterating the dict directly gives you keys. .values() gives values. .items() gives both at once and is what you will use most: unpack each pair into two names for clean, readable loops.
player = {"name": "Alice", "score": 87, "level": 5}
for key in player: # iterate keys (most common)
print(key)
for key in player.keys(): # same, explicit keys view
print(key)
for value in player.values(): # the values
print(value)
for key, value in player.items(): # both, most useful
print(f"{key}: {value}").items() is what you will use most. Unpacking each pair into two names makes the loop readable.
.values() gives the values, and .items() gives both at once, which is the one you'll reach for most. Unpacking each pair into two names like for key, value in player.items() made my loops so much easier to read. Checking membership
in checks whether a key exists in the dictionary. It does not check values, only keys. To check whether something is not present, use not in.
player = {"name": "Alice", "score": 87}
"name" in player # True
"lives" in player # False
"lives" not in player # Truein only checks keys. To check values, use in player.values(), though that is rarely needed.
in tells you whether a key is in the dict, and only a key, never a value. It stays fast no matter how big the dict gets. Flip it to not in to check that something is absent. Nested dictionaries
Values can be dictionaries themselves. This is how you represent structured data with multiple levels: a player that has a stats section, a config file with sub-sections. Two sets of square brackets access a nested value: the first picks the outer key, the second picks the inner key.
users = {
"alice": {"score": 87, "level": 5},
"bob": {"score": 74, "level": 3},
}
users["alice"]["score"] # 87
users["bob"]["level"] # 3Access with chained square brackets. For deeply nested structures, this can get unwieldy, so keep nesting shallow where you can.
setdefault
.setdefault() reads a key if it exists, or sets it to a default value if it does not, then returns the value. It is useful when you need a key to exist but do not want to overwrite it if it is already there.
inventory = {}
inventory.setdefault("arrows", 0) # sets "arrows": 0, returns 0
inventory.setdefault("arrows", 10) # "arrows" already exists, no change, returns 0It is useful for building up grouped structures without checking for key existence first:
groups = {}
for name, team in players:
groups.setdefault(team, []).append(name).setdefault(key, default) reads a key if it's there, or sets it to the default and returns it if it isn't. It's the tidy way to make sure a key exists without clobbering a value that's already in. I use it most for grouping things, no "is this key here yet?" check needed. collections.defaultdict and Counter
The standard library has two dict subclasses that handle common patterns automatically. defaultdict creates a default value for missing keys so you never get a KeyError. Counter counts how often each item appears in a sequence and gives you the results as a dict.
defaultdict and Counter live in the standard library, so they need importing first. Imports get full treatment in the Modules chapter.
from collections import defaultdict
groups = defaultdict(list)
for name, team in players:
groups[team].append(name) # no KeyError if team is newfrom collections import Counter
words = ["cat", "dog", "cat", "bird", "cat", "dog"]
counts = Counter(words)
# Counter({'cat': 3, 'dog': 2, 'bird': 1})
counts.most_common(2) # [('cat', 3), ('dog', 2)]Counter saves a lot of "count things in a loop" boilerplate.
defaultdict fills in a default for any missing key, so grouping and counting stop throwing KeyError at you. Counter tallies how often each item shows up in a sequence and hands it back as a dict. The first time I swapped a hand-written counting loop for Counter, half my code vanished. In practice
Building a score tracker and printing a summary with all entries:
scores = {"Alice": 87, "Bob": 74, "Carol": 92, "Dave": 55}
total = sum(scores.values())
average = total / len(scores)
print(f"Players: {len(scores)}")
print(f"Average: {average:.1f}")
print(f"Highest: {max(scores.values())}")
print(f"Lowest: {min(scores.values())}")
print()
for name, score in scores.items():
print(f" {name}: {score}")