Lists
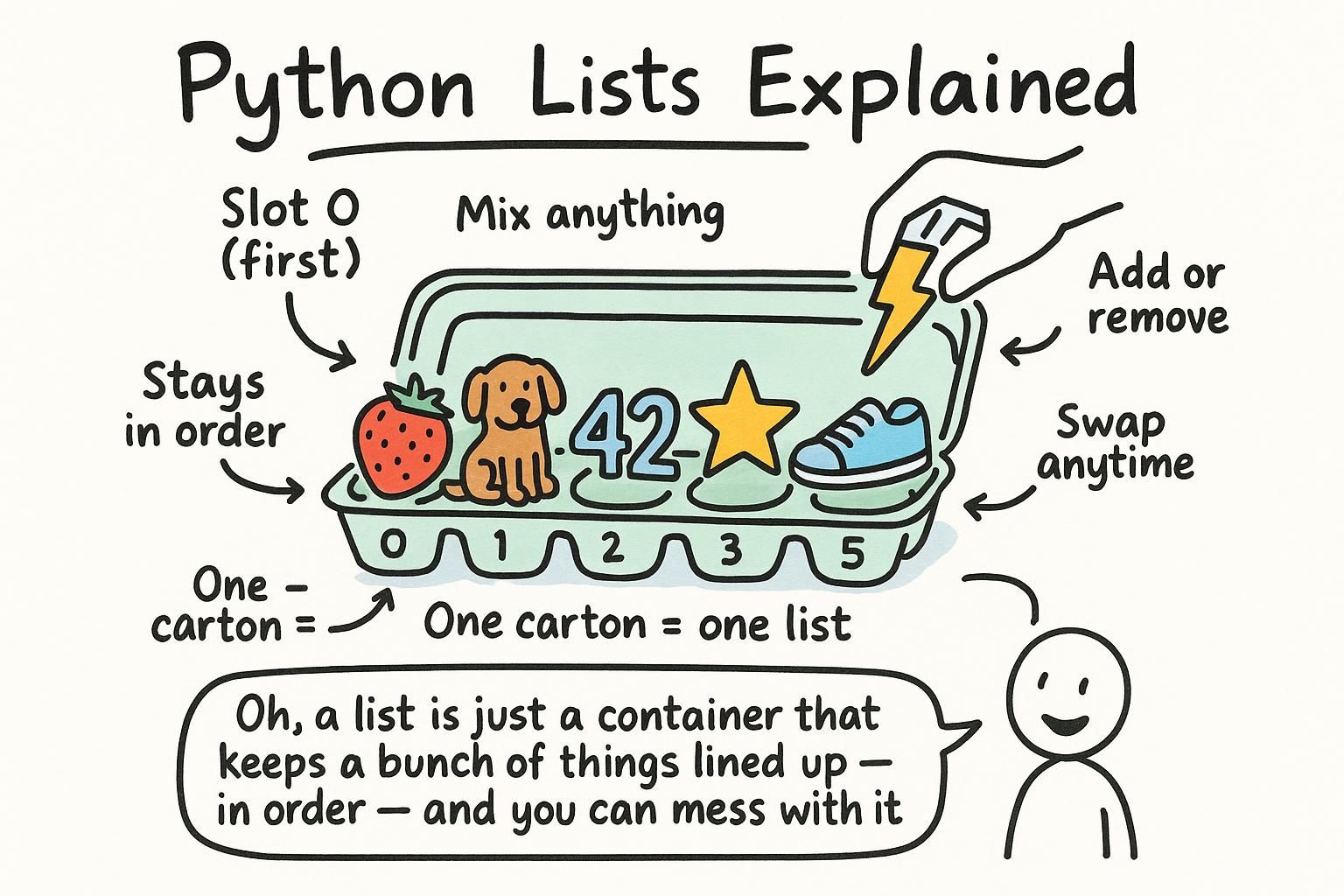
A variable holds one thing. A list holds many things in order, all under one name. A leaderboard is a ranked sequence of scores. A quiz is a collection of questions. Once you need to manage a group of related values, you need a list.
Creating a list
Square brackets, values separated by commas. Lists can hold any mix of types, and an empty list is valid and common as a starting point you build up over time.
scores = [87, 92, 74, 65, 91]
players = ["Alice", "Bob", "Charlie"]
mixed = ["Alice", 87, True, 3.14] # any types, though uncommon
empty = []
[] is a fine starting point when you plan to fill it up as you go. Most of my lists start out that way, empty and waiting. Indexing and slicing
Lists use the same numbering as strings: positions start at 0, negative numbers count from the end. You read any item by its position. Because lists are mutable, you can also write to a specific position.
scores = [87, 92, 74, 65, 91]
scores[0] # 87 (first)
scores[-1] # 91 (last)
scores[1:3] # [92, 74]
scores[:2] # [87, 92]
scores[::-1] # [91, 65, 74, 92, 87] (reversed)
scores[0] = 90 # mutable: works (strings would raise TypeError)0, and negative numbers count back from the end, so scores[-1] is the last one. A slice like scores[1:3] hands you a fresh list with positions 1 and 2. The part that took me a moment: with a list you can also write to a position, scores[0] = 90, where a string would refuse. Adding items
Three methods to add items. append() adds a single item to the end and is what you will use almost every time. insert() adds at a specific position. extend() merges another list in.
scores = [87, 92, 74]
scores.append(65) # [87, 92, 74, 65]
scores.insert(1, 100) # [87, 100, 92, 74, 65]
scores.extend([55, 71]) # [87, 100, 92, 74, 65, 55, 71]A common mistake: append() with a list adds the whole list as one item, giving you a list inside a list. Use extend() to merge instead:
scores.append([55, 71]) # [..., [55, 71]] nested list, probably wrong
scores.extend([55, 71]) # [..., 55, 71] merged, correctappend() tacks one item onto the end and is what you will reach for nearly every time. insert() drops an item at a position, extend() merges another list in. The classic slip: append() a list and you get a list inside your list, so use extend() when you mean to merge. Removing items
Four tools to remove items. remove() searches by value. pop() removes by position and hands you the item back. del removes by position without a return value. clear() empties the whole list.
scores = [87, 92, 74, 65, 91]
scores.remove(74) # removes first occurrence of 74
scores.pop() # removes and returns last item (91)
scores.pop(0) # removes and returns item at position 0 (87)
del scores[1] # removes at position 1, no return value
scores.clear() # removes everythingremove() raises a ValueError if the value is not in the list. Check with in first if you are not certain:
if 74 in scores:
scores.remove(74)remove() deletes by value and only the first match, and it raises ValueError if the value is not there, so check with in first when you are not sure. pop() removes by position and hands the item back, del removes by position and hands you nothing. Sorting
sorted() returns a brand new sorted list and leaves your original untouched. .sort() sorts the list in place and returns None. That difference matters more than it sounds.
scores = [87, 42, 96, 55, 71]
ranked = sorted(scores) # [42, 55, 71, 87, 96] (new list)
scores.sort() # sorts in place, returns None
scores.sort(reverse=True) # [96, 87, 71, 55, 42]
result = scores.sort() # result is None, not the sorted listsorted() gives you a new sorted list and leaves the original alone. .sort() rearranges the list itself and returns None, so x = scores.sort() lands you with None, not the list. I made that exact mistake more than once before it stuck. Useful operations
Python has a set of built-in tools that work directly on lists. len(), sum(), min(), and max() are the four you will reach for constantly.
scores = [87, 92, 74, 65, 91]
len(scores) # 5
sum(scores) # 409
min(scores) # 65
max(scores) # 92
scores.count(87) # 1
scores.index(74) # 2
74 in scores # True
74 not in scores # False
scores.copy() # shallow copy
scores.reverse() # reverses in placelen(), sum(), min(), and max() all work straight on a list, no setup. in asks whether something is present, .count() tallies how many times, and .index() finds the position of the first match. Iterating
A for loop goes through a list one item at a time. The variable after for receives each item in turn. When you also need the position, enumerate() gives you both without a manual counter.
players = ["Alice", "Bob", "Charlie"]
for player in players:
print(player)
for i, player in enumerate(players, start=1):
print(f"{i}. {player}")
# 1. Alice
# 2. Bob
# 3. Charliefor and enumerate() get full treatment in the Control flow chapter. The short version: for player in players runs once per item, and enumerate() gives you both the position and the value on every iteration.
for loop walks the list one item at a time, and the name after for becomes that item each turn. When you want the position too, enumerate() hands you both, so you never have to keep a counter yourself. Letting it count for me saved me a pile of off-by-one slips. Nested lists
A list can contain other lists. This is how you represent a grid or a table: a list of rows, each row being a list of values. Two sets of square brackets access an item: the first picks the row, the second picks the column.
grid = [
[1, 2, 3],
[4, 5, 6],
[7, 8, 9],
]
grid[0] # [1, 2, 3]
grid[1][2] # 6 (row 1, column 2)grid[1][2], the first picks the row, the second picks from it. Mutability: the gotcha
This surprises almost everyone. Assigning a list to a new variable does not make a copy. Both names point at the same list. Change one and you change the other. To get an independent copy, you have to ask for one explicitly.
a = [1, 2, 3]
b = a # b is not a copy; it points at the same list
b.append(4)
print(a) # [1, 2, 3, 4] (changed: a and b are the same list)b = a.copy() # independent copy
b = list(a) # same result
b = a[:] # also the same
# Nested lists still share their inner objects:
matrix = [[1, 2], [3, 4]]
copy = matrix.copy()
copy[0].append(99)
print(matrix) # [[1, 2, 99], [3, 4]] (inner list was shared)b = a does not make a copy, both names point at the same list, so a change through one shows through the other. For an independent list you have to ask: .copy(), list(a), or a[:]. This one surprises almost everyone the first time, me included. More methods
| Method | What it does |
|---|---|
.append(item) | Add to the end |
.insert(i, item) | Insert at position i |
.extend(iterable) | Add all items from an iterable |
.remove(value) | Remove first occurrence of value |
.pop(i) | Remove and return item at position i (default: last) |
.clear() | Remove all items |
.index(value) | Position of first occurrence |
.count(value) | Number of occurrences |
.sort() | Sort in place |
.reverse() | Reverse in place |
.copy() | Return a shallow copy |
In practice
Building a score tracker: add results, sort them, and print a summary.
scores = []
scores.append(87)
scores.append(54)
scores.append(92)
scores.append(67)
scores.append(45)
scores.sort(reverse=True)
print(f"Ranked scores: {scores}")
print(f"Highest: {scores[0]}")
print(f"Lowest: {scores[-1]}")
print(f"Average: {sum(scores) / len(scores):.1f}")
print(f"Top 3: {scores[:3]}")