列表
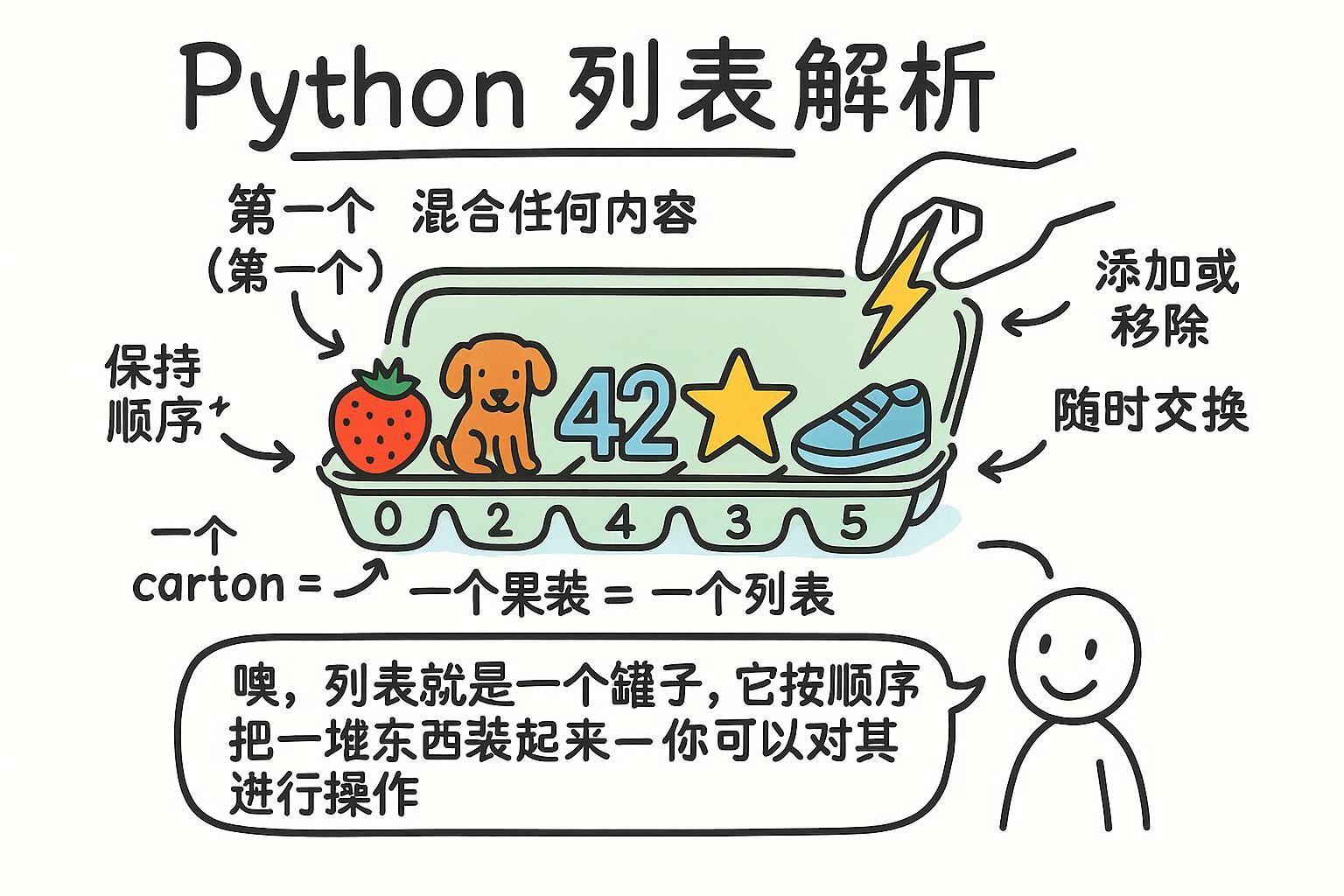
一个变量存放一件东西。一个列表按顺序存放许多东西,都放在一个名字下面。排行榜是一个排名的分数序列。一个测验是一组问题的集合。一旦你需要管理一组相关的值,你就需要一个列表。
创建列表
方括号,值用逗号分隔。列表可以包含任何类型的混合,空列表作为起点是有效且常见的,你可以随着时间的推移逐步构建。
scores = [87, 92, 74, 65, 91]
players = ["李明", "王强", "张芳"]
mixed = ["李明", 87, True, 3.14] # 任何类型,尽管不常见
empty = []
[] 是一个很好的起点,当你计划逐渐填充它时。我的大多数列表都是这样开始的,空的,等待被填充。 索引和切片
列表使用与字符串相同的编号:位置从 0 开始,负数从末尾向后计数。你可以通过位置读取任何项。因为列表是可变的,你也可以写入到特定位置。
scores = [87, 92, 74, 65, 91]
scores[0] # 87 (第一个)
scores[-1] # 91 (最后一个)
scores[1:3] # [92, 74]
scores[:2] # [87, 92]
scores[::-1] # [91, 65, 74, 92, 87] (反向)
scores[0] = 90 # 可变:有效(字符串会抛出 TypeError)0 开始,负数从末尾向后计数,所以 scores[-1] 是最后一个。一个像 scores[1:3] 这样的切片给你一个包含位置 1 和 2 的新列表。让我花了一会儿的部分:对于列表,你也可以写入一个位置,scores[0] = 90,而字符串会拒绝。 添加项
有三种方法可以添加项。append() 在末尾添加单个项,这几乎是你每次都会使用的。insert() 在特定位置添加。extend() 合并另一个列表。
scores = [87, 92, 74]
scores.append(65) # [87, 92, 74, 65]
scores.insert(1, 100) # [87, 100, 92, 74, 65]
scores.extend([55, 71]) # [87, 100, 92, 74, 65, 55, 71]常见的错误:用一个列表调用 append() 会添加整个列表作为一个项,给你一个列表内的列表。使用 extend() 来合并:
scores.append([55, 71]) # [..., [55, 71]] 嵌套列表,可能有问题
scores.extend([55, 71]) # [..., 55, 71] 合并,正确append() 将一个项添加到末尾,这几乎每次都是你会使用的。insert() 在位置放入一个项,extend() 合并另一个列表。经典的错误:append() 一个列表,你会得到列表中的列表,所以当你想合并时使用 extend()。 移除项
有四种工具来移除项。remove() 按值搜索。pop() 按位置移除并将项返回给你。del 按位置移除,没有返回值。clear() 清空整个列表。
scores = [87, 92, 74, 65, 91]
scores.remove(74) # 移除第一个 74
scores.pop() # 移除并返回最后一项 (91)
scores.pop(0) # 移除并返回位置 0 的项 (87)
del scores[1] # 移除位置 1,没有返回值
scores.clear() # 移除所有东西如果列表中没有该值,remove() 会抛出 ValueError。如果你不确定,先用 in 检查:
if 74 in scores:
scores.remove(74)remove() 按值删除,只有第一个匹配,如果值不在那里会抛出 ValueError,所以当你不确定时先用 in 检查。pop() 按位置移除并返回项,del 按位置移除并什么都不返回给你。 排序
sorted() 返回一个全新的已排序列表,留下你的原始列表未触及。.sort() 就地排序列表并返回 None。这个区别的重要性超出了人们的想象。
scores = [87, 42, 96, 55, 71]
ranked = sorted(scores) # [42, 55, 71, 87, 96] (新列表)
scores.sort() # 就地排序,返回 None
scores.sort(reverse=True) # [96, 87, 71, 55, 42]
result = scores.sort() # result 是 None,不是排序后的列表sorted() 给你一个新的排序列表,留下原始不变。.sort() 重新排列列表本身并返回 None,所以 x = scores.sort() 会让你得到 None,不是列表。我在它真正记住之前做过多次这个确切的错误。 有用的操作
Python 有一组内置工具直接对列表工作。len()、sum()、min() 和 max() 是你将不断使用的四个。
scores = [87, 92, 74, 65, 91]
len(scores) # 5
sum(scores) # 409
min(scores) # 65
max(scores) # 92
scores.count(87) # 1
scores.index(74) # 2
74 in scores # True
74 not in scores # False
scores.copy() # 浅复制
scores.reverse() # 就地反向len()、sum()、min() 和 max() 都直接对列表工作,无需设置。in 询问某物是否存在,.count() 统计出现多少次,.index() 找到第一个匹配的位置。 迭代
一个 for 循环逐个遍历列表的项。for 后的变量依次接收每个项。当你也需要位置时,enumerate() 在不使用手动计数器的情况下给你两者。
players = ["李明", "王强", "张芳"]
for player in players:
print(player)
for i, player in enumerate(players, start=1):
print(f"{i}. {player}")
# 1. 李明
# 2. 王强
# 3. 张芳for 和 enumerate() 在控制流章节获得完整处理。简短版本:for player in players 为每个项运行一次,enumerate() 在每次迭代时给你位置和值。
嵌套列表
一个列表可以包含其他列表。这是你如何表示网格或表格的方式:行的列表,每行是值的列表。两组方括号访问一个项:第一个选择行,第二个选择列。
grid = [
[1, 2, 3],
[4, 5, 6],
[7, 8, 9],
]
grid[0] # [1, 2, 3]
grid[1][2] # 6 (行 1,列 2)grid[1][2],第一个选择行,第二个从中选择。 可变性:陷阱
这令几乎每个人都惊讶。将列表分配给新变量不会制作复制。两个名字指向同一个列表。改变一个,你改变另一个。要获得独立的副本,你必须明确要求一个。
a = [1, 2, 3]
b = a # b 不是副本;它指向同一个列表
b.append(4)
print(a) # [1, 2, 3, 4] (改变:a 和 b 是同一个列表)b = a.copy() # 独立副本
b = list(a) # 相同结果
b = a[:] # 也是相同
# 嵌套列表仍然共享它们的内部对象:
matrix = [[1, 2], [3, 4]]
copy = matrix.copy()
copy[0].append(99)
print(matrix) # [[1, 2, 99], [3, 4]] (内部列表被共享)b = a 不制作副本,两个名字指向同一个列表,所以通过一个的改变通过另一个显示。对于独立列表,你必须要求:.copy()、list(a) 或 a[:]。这个第一次令几乎每个人都惊讶,包括我。 更多方法
| 方法 | 做什么 |
|---|---|
.append(item) | 添加到末尾 |
.insert(i, item) | 在位置 i 插入 |
.extend(iterable) | 从可迭代的添加所有项 |
.remove(value) | 移除值的第一个匹配 |
.pop(i) | 移除并返回位置 i 的项(默认:最后一个) |
.clear() | 移除所有项 |
.index(value) | 第一个匹配的位置 |
.count(value) | 匹配的数量 |
.sort() | 就地排序 |
.reverse() | 就地反向 |
.copy() | 返回浅复制 |
实践中
构建一个分数跟踪器:添加结果,排序它们,并打印摘要。
scores = []
scores.append(87)
scores.append(54)
scores.append(92)
scores.append(67)
scores.append(45)
scores.sort(reverse=True)
print(f"排序的分数:{scores}")
print(f"最高:{scores[0]}")
print(f"最低:{scores[-1]}")
print(f"平均值:{sum(scores) / len(scores):.1f}")
print(f"前 3:{scores[:3]}")