字典
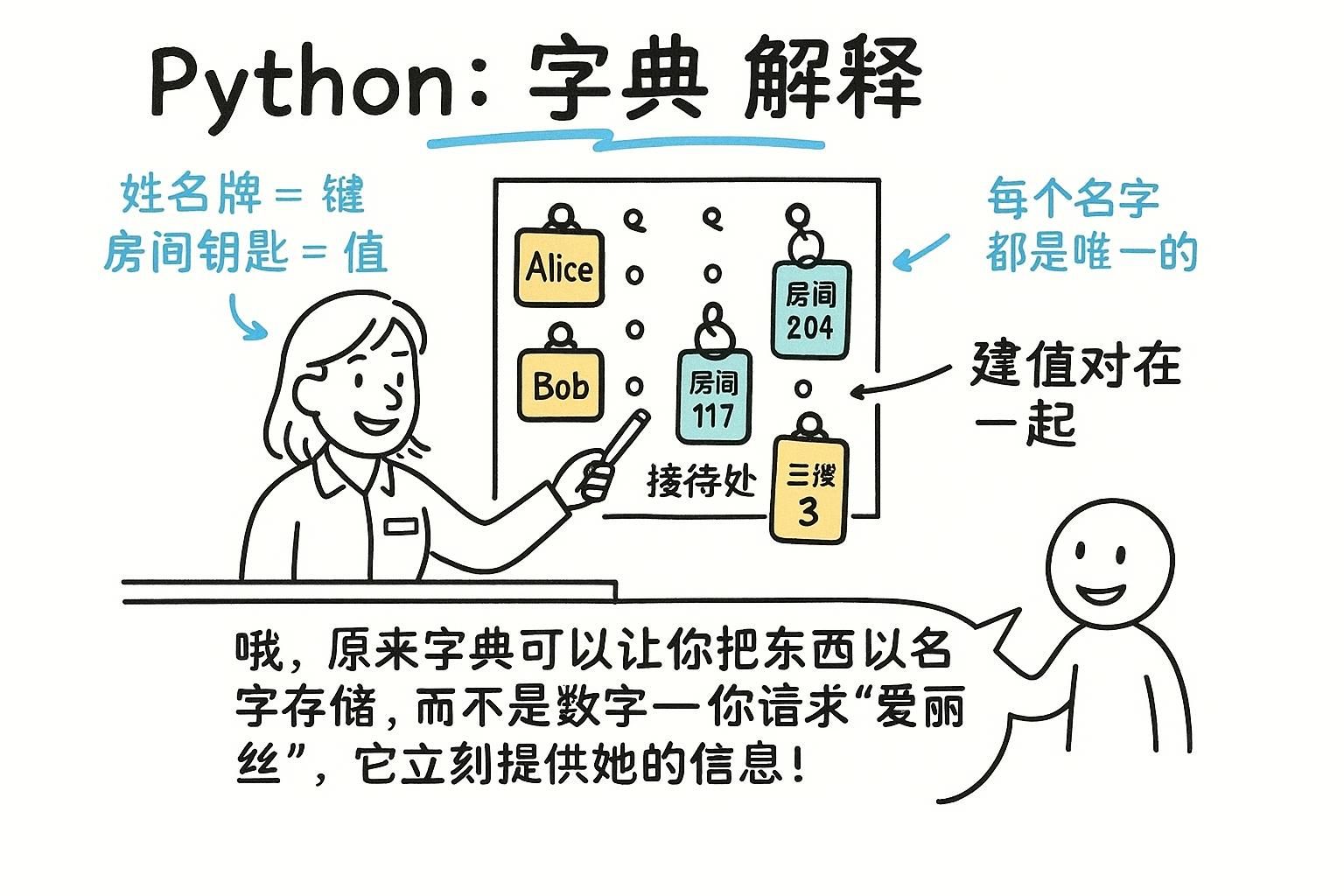
列表让你按位置查找内容。但通常你想按名称查找。不是"给我第 3 项",而是"给我李明的分数"。字典将数据存储为键值对:你按键而不是位置查找值。
创建字典
大括号,每个键和值之间加冒号,对之间加逗号。键几乎总是字符串。值可以是任何东西:数字、字符串、其他列表,甚至其他字典。
player = {
"name": "张三",
"score": 87,
"level": 5,
"alive": True,
}
访问值
使用方括号和键获取值。如果键不存在,Python 会引发 KeyError。当你不确定键是否存在时,使用 .get():它返回 None 而不是崩溃,或者返回你指定的默认值。
player = {"name": "张三", "score": 87}
player["name"] # "张三"
player["score"] # 87
player["lives"] # KeyError (键不存在)player.get("score") # 87
player.get("lives") # None (无错误,默认返回 None)
player.get("lives", 3) # 3 (如果键不存在使用此默认值)当键可能缺失时,.get() 更安全:
count = inventory.get("arrows", 0) # 如果字典中没有 "arrows",返回 0d["key"] 给你值,但如果那个键不在那里会引发 KeyError。当你不确定时,选择 .get():它返回 None 而不是崩溃,或者返回你传入的默认值。我现在将所有东西都默认化,我的程序停止因缺失键而崩溃。 添加和更新
使用方括号分配到键。如果键已存在,值被替换。如果还不存在,创建新条目。使用 .update() 一次性合并整个其他字典。
player = {"name": "张三", "score": 87}
player["score"] = 92 # 更新现有的
player["level"] = 5 # 添加新键extras = {"level": 5, "alive": True}
player.update(extras) # 使用 extras 中的键添加/覆盖.update() 一次性合并整个其他字典。 移除项
四种移除条目的方式。.pop() 移除键并返回值。带默认值的 .pop() 在键可能不存在时很安全。del 移除键,无返回值。.clear() 清空整个字典。
player = {"name": "张三", "score": 87, "level": 5}
player.pop("level") # 移除 "level" 并返回 5
player.pop("lives", None) # 安全的 pop,如果键不存在返回 None
del player["score"] # 移除 "score",无返回值
player.clear() # 移除所有内容带默认值的 .pop() 是移除可能不存在的键的最安全方式。
.pop(key) 移除键并返回它的值,而 .pop(key, None) 在键可能不存在时保持冷静。del d[key] 移除不返回任何东西,.clear() 清空整个东西。.pop() 上的默认值救了我免遭很多 KeyError 惊喜。 迭代
三个视图让你循环字典的不同部分。直接迭代字典给你键。.values() 给值。.items() 一次给出两个,这是你最常用的:将每对解包成两个名称以获得清晰、可读的循环。
player = {"name": "张三", "score": 87, "level": 5}
for key in player: # 迭代键(最常见)
print(key)
for key in player.keys(): # 相同,显式键视图
print(key)
for value in player.values(): # 值
print(value)
for key, value in player.items(): # 两者,最有用
print(f"{key}: {value}").items() 是你最常用的。将每对解包成两个名称使循环可读。
.values() 给值,.items() 一次给两个,这是你最常选择的。将每对解包成两个名称像 for key, value in player.items() 使我的循环更容易读得多。 检查成员
in 检查字典中是否存在键。它不检查值,只检查键。要检查某物是否不存在,使用 not in。
player = {"name": "张三", "score": 87}
"name" in player # True
"lives" in player # False
"lives" not in player # Truein 只检查键。要检查值,使用 in player.values(),虽然很少需要。
in 告诉你一个键是否在字典中,只有一个键,永远不是值。无论字典多大它都保持快速。将其翻转为 not in 检查某物是否不存在。 嵌套字典
值本身可以是字典。这是表示具有多个级别的结构化数据的方式:具有统计部分的玩家、具有子部分的配置文件。两组方括号访问嵌套值:第一个选择外部键,第二个选择内部键。
users = {
"alice": {"score": 87, "level": 5},
"bob": {"score": 74, "level": 3},
}
users["alice"]["score"] # 87
users["bob"]["level"] # 3用链式方括号访问。对于深度嵌套的结构,这可能变得笨拙,所以尽可能保持嵌套浅层。
setdefault
.setdefault() 读取一个键如果它存在,或如果它不存在则将其设置为默认值,然后返回值。当你需要键存在但不想覆盖它已经在那里时很有用。
inventory = {}
inventory.setdefault("arrows", 0) # 设置 "arrows": 0,返回 0
inventory.setdefault("arrows", 10) # "arrows" 已存在,无改变,返回 0它对在不首先检查键存在的情况下构建分组结构很有用:
groups = {}
for name, team in players:
groups.setdefault(team, []).append(name).setdefault(key, default) 读取一个键如果它在那里,或如果它不在的话设置为默认值并返回它。这是确保键存在的整洁方式,不会破坏已经存在的值。我最常用它来分组东西,无需"这个键在这里吗?"检查。 collections.defaultdict 和 Counter
标准库有两个字典子类,自动处理常见模式。defaultdict 为缺失键创建默认值所以你永远不会得到 KeyError。Counter 计数序列中每个项出现多少次并将结果作为字典提供。
defaultdict 和 Counter 在标准库中,所以它们需要首先导入。导入在模块章节获得完整处理。
from collections import defaultdict
groups = defaultdict(list)
for name, team in players:
groups[team].append(name) # 如果 team 是新的无 KeyErrorfrom collections import Counter
words = ["cat", "dog", "cat", "bird", "cat", "dog"]
counts = Counter(words)
# Counter({'cat': 3, 'dog': 2, 'bird': 1})
counts.most_common(2) # [('cat', 3), ('dog', 2)]Counter 节省大量"在循环中计数东西"样板。
defaultdict 为任何缺失键填充默认值,所以分组和计数停止对你抛出 KeyError。Counter 统计项在序列中出现多少次并作为字典交回。第一次我用 Counter 交换了一个手写计数循环,半个我的代码消失了。 实践中
构建分数跟踪器并打印包含所有条目的摘要:
scores = {"张三": 87, "李四": 74, "王五": 92, "赵六": 55}
total = sum(scores.values())
average = total / len(scores)
print(f"玩家: {len(scores)}")
print(f"平均: {average:.1f}")
print(f"最高: {max(scores.values())}")
print(f"最低: {min(scores.values())}")
print()
for name, score in scores.items():
print(f" {name}: {score}")