字符串
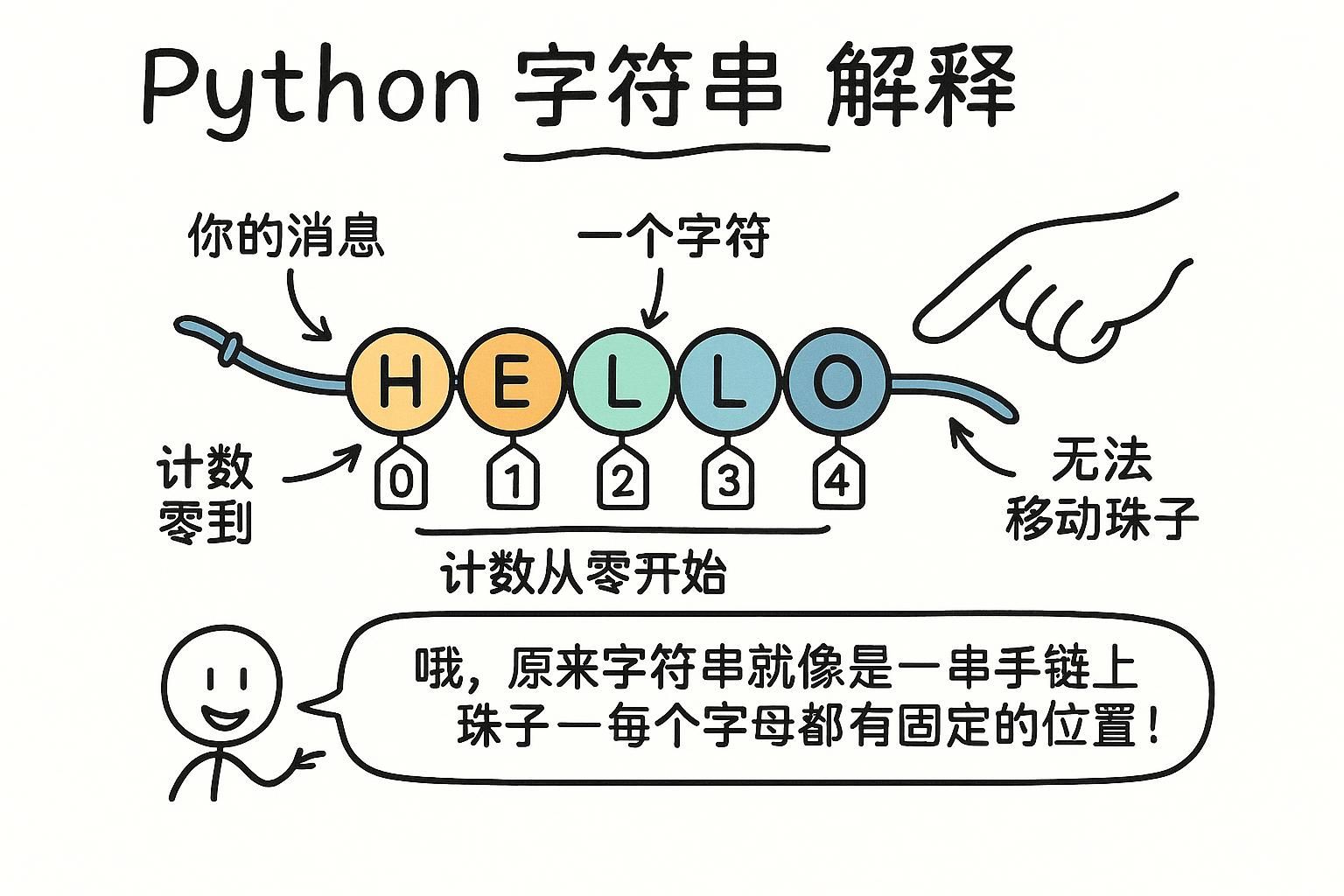
文本出现在几乎所有你编写的程序中。名字、消息、分数、标签。在 Python 中,任何一段文本都称为字符串:任何用引号括起来的值。单引号或双引号,两者的工作方式相同。
greeting = "Hello, world"
username = 'zhang'引号选择重要的唯一时刻是当你的文本包含引号时。使用相反的风格,这样你就不必转义它们:
note = "It's a great day" # 内部包含撇号,使用双引号
message = 'She said "hello"' # 内部包含双引号,使用单引号
escaped = "She said \"hello\"" # 或用反斜杠转义不可变性
字符串是不可变的:创建后,无法更改。把字符串看作在创建的瞬间永久固定。任何看起来像在修改字符串的操作实际上是产生了一个全新的字符串。原始字符串保持完全不变。
name = "zhang"
name = name.upper() # "ZHANG" 是一个新字符串;"zhang" 保持不变直接的结果:无法更改特定位置的字符。如果尝试,Python 会引发错误。
name = "zhang"
name[0] = "Z" # TypeError: 'str' object does not support item assignment要获得修改后的字符串,使用切片或方法构建一个新的。两者都将在下面介绍。

name[0] = "Z" 不起作用,它会引发 TypeError。 索引和切片
字符串中的每个字符都有一个编号位置,从零开始。你可以通过将该位置号放在方括号中来读取单个字符。负数从末尾向后计数。
word = "Python"
# 012345
print(word[0]) # "P"
print(word[2]) # "t"
print(word[5]) # "n"
print(word[-1]) # "n" (最后一个字符)
print(word[-2]) # "o" (倒数第二个)-1 总是最后一个字符,-2 是倒数第二个,以此类推。当你想要字符串的末尾而不知道其确切长度时,它们很有用。
切片提取一个块。[start:stop] 包括 start 并排除 stop:
word = "Python"
print(word[0:2]) # "Py" (位置 0 和 1)
print(word[2:]) # "thon" (位置 2 到末尾)
print(word[:3]) # "Pyt" (开始到位置 2)
print(word[:]) # "Python" (整个字符串的副本)
print(word[::2]) # "Pto" (每隔一个字符)
print(word[::-1]) # "nohtyP" (反转)最常用的三种模式:word[:n] 用于前 n 个字符,word[n:] 用于位置 n 及以后的所有内容,word[-n:] 用于最后 n 个字符。word[::-1] 反转字符串。第一次看起来很奇怪,但这是惯用的 Python,你会经常看到它。
word[0] 是第一个字符,word[-1] 是最后一个。切片抓住一个范围:word[start:stop] 保持 start 并在 stop 之前停止。word[::-1] 反转字符串,第一次看起来很奇怪,然后你永远使用它。 基本字符串方法
字符串配备了一套内置方法:可以直接在任何字符串值上调用的操作。你写字符串(或持有它的变量),然后一个点,然后方法名。每个方法返回一个新字符串。原始字符串永不更改。
大小写
text = "Hello, World"
text.lower() # "hello, world"
text.upper() # "HELLO, WORLD"
text.title() # "Hello, World" (每个单词大写)
text.capitalize() # "Hello, world" (仅第一个单词)lower() 和 upper() 是你将最频繁使用的两个。lower() 特别适用于比较文本:"Alice" 和 "alice" 在对两边调用 .lower() 后变成相同的东西。
空白
text = " hello "
text.strip() # "hello" (两边)
text.lstrip() # "hello " (仅左边)
text.rstrip() # " hello" (仅右边)strip() 从字符串的两端移除空格。几乎任何时候你处理用户输入或来自文件的文本时,你都会使用它,因为杂散的空格导致无声失败:"alice" != "alice "。
查找
text = "Hello, world"
text.find("world") # 7
text.find("Python") # -1 (未找到)
text.count("l") # 3
text.startswith("Hello") # True
text.endswith("world") # Truefind() 返回字符串内一段文本开始的位置。如果不在那里,它返回 -1。当你只关心字符串是否以特定的东西开始或结束时,使用 startswith() 和 endswith()。
替换
text = "Hello, world"
text.replace("world", "Python") # "Hello, Python"
text.replace("l", "L") # "HeLLo, worLd" (所有出现)
text.replace("l", "L", 1) # "HeLlo, world" (仅第一个)replace() 用另一段文本交换一段文本的每个出现,并给你返回一个新字符串。原始不更改。如果你只想替换第一个出现,传递第三个参数。
分割和连接
split() 在分隔符处将字符串切成块并以列表形式返回。你告诉它要切什么:
csv_row = "Zhang,28,Beijing"
parts = csv_row.split(",") # ["Zhang", "28", "Beijing"]
" hello world ".split() # ["hello", "world"]split() 返回一个列表,一个有序的值序列。它们有自己的列表章节;现在将它们视为 split() 产生和 join() 消费的部分序列。
join() 做相反的:它将一个字符串列表组合成一个。.join() 之前的字符串被放在每个项之间:
words = ["Hello", "world"]
" ".join(words) # "Hello world"
", ".join(words) # "Hello, world"
"".join(words) # "Helloworld"要记住的模式:separator.join(list_of_strings)。分隔符在左边,列表在右边。" ".join(words) 在每个单词之间放一个空格。"".join(words) 中间什么都没有地粘合它们。
.lower() 和 .upper() 用于大小写,.strip() 用于修剪杂散空格,.find() 来定位文本(当找不到时返回 -1),.replace() 来交换文本,以及 .split() 配合 sep.join() 来将字符串分开并重新组装。 f-字符串
f-字符串直接在文本内嵌入值。在开始引号前放 f,然后将任何变量或表达式包装在花括号中。Python 在代码运行时填充它。你也可以在值后面添加冒号来控制它的显示方式。
name = "Zhang"
score = 94.5
print(f"Hello, {name}!") # "Hello, Zhang!"
print(f"Score: {score:.1f}%") # "Score: 94.5%"
print(f"2 + 2 = {2 + 2}") # "2 + 2 = 4"
print(f"Name: {name.upper()}") # "Name: ZHANG"冒号后的格式规范控制值的显示方式:
| 规范 | 含义 | 示例 |
|---|---|---|
.2f | 2 位小数 | f"{3.14159:.2f}" → "3.14" |
.0% | 百分比,无小数 | f"{0.94:.0%}" → "94%" |
, | 千位分隔符 | f"{1000000:,}" → "1,000,000" |
>10 | 在 10 个字符中右对齐 | f"{'hi':>10}" → " hi" |
你会最频繁地使用 .2f:任何时候你显示小数并想要整洁的数字而不是很长的数字运行。表中的所有其他内容在你需要时都在那里。你可以在 {} 内放任何变量、算术或方法调用。
f,然后将任何变量、求和或方法调用包装在 {} 中,Python 在行运行时将结果放进去。{} 内的冒号控制外观::.2f 用于两位小数是你将依赖的那个。远比用 + 粘合文本更整洁。 多行字符串
要写跨越多行的字符串,使用三个引号:开始处三个 " 和末尾三个。Python 完全按照你写它们的方式保留所有换行符和间距。
message = """
Dear Zhang,
Thank you for your order.
Best regards,
The Team
"""转义序列
一些字符很难直接在字符串内键入。Python 使用转义序列:一个反斜杠后跟一个代表某些东西的字母。你将不断使用的两个是 \n 用于新行和 \t 用于制表符。
| 序列 | 字符 |
|---|---|
\n | 换行 |
\t | 制表符 |
\\ | 文字反斜杠 |
\" | 双引号 |
\' | 单引号 |
print("Line one\nLine two") # 两行输出
print("Name:\tZhang") # Name: Zhang
path = r"C:\Users\Zhang\Documents" # 原始字符串,无转义处理\n 开始新行,\t 插入制表符,\\ 是一个真正的反斜杠。那两个,\n 和 \t,是你实际会键入的。在引号前弹出 r 并且反斜杠回到普通,便利用于 Windows 路径。 检查字符串内容
Python 有方法回答关于字符串包含什么的是-否问题。它们返回 True 或 False。最早有用的:isdigit() 让你检查一个字符串是否全是数字后转换它,所以你可以避免在意外输入上崩溃。
"42".isdigit() # True
"hello".isalpha() # True
"hello42".isalnum() # True
" ".isspace() # True
"Hello".islower() # False
"HELLO".isupper() # Trueis* 方法回答是-否问题并仅当每个字符适合时返回 True。你首先会使用的那个:在 int() 前调用 isdigit() 确保文本真是一个数字,所以奇怪输入不会崩溃你。 实践中
剥离空白,规范化大小写,然后拉出你需要的。这个序列处理几乎任何用户提供的文本:
raw_input = " [email protected] "
email = raw_input.strip().lower() # "[email protected]"
at_pos = email.find("@")
username = email[:at_pos]
domain = email[at_pos + 1:]
print(f"User: {username}") # "zhang"
print(f"Domain: {domain}") # "example.com"方法参考
| 方法 | 作用 |
|---|---|
.lower() / .upper() | 转换为全小写 / 全大写 |
.title() / .capitalize() | 大写每个单词 / 仅第一个 |
.strip() / .lstrip() / .rstrip() | 移除周围空白 |
.find(sub) | 第一个匹配的索引,或 -1 |
.count(sub) | sub 出现的次数 |
.startswith(s) / .endswith(s) | 前缀 / 后缀检查 |
.replace(old, new) | 替换出现 |
.split(sep) | 分割为列表 |
sep.join(iterable) | 连接项成字符串 |
.isdigit() / .isalpha() / .isalnum() | 字符类型检查 |