स्ट्रिंग्स
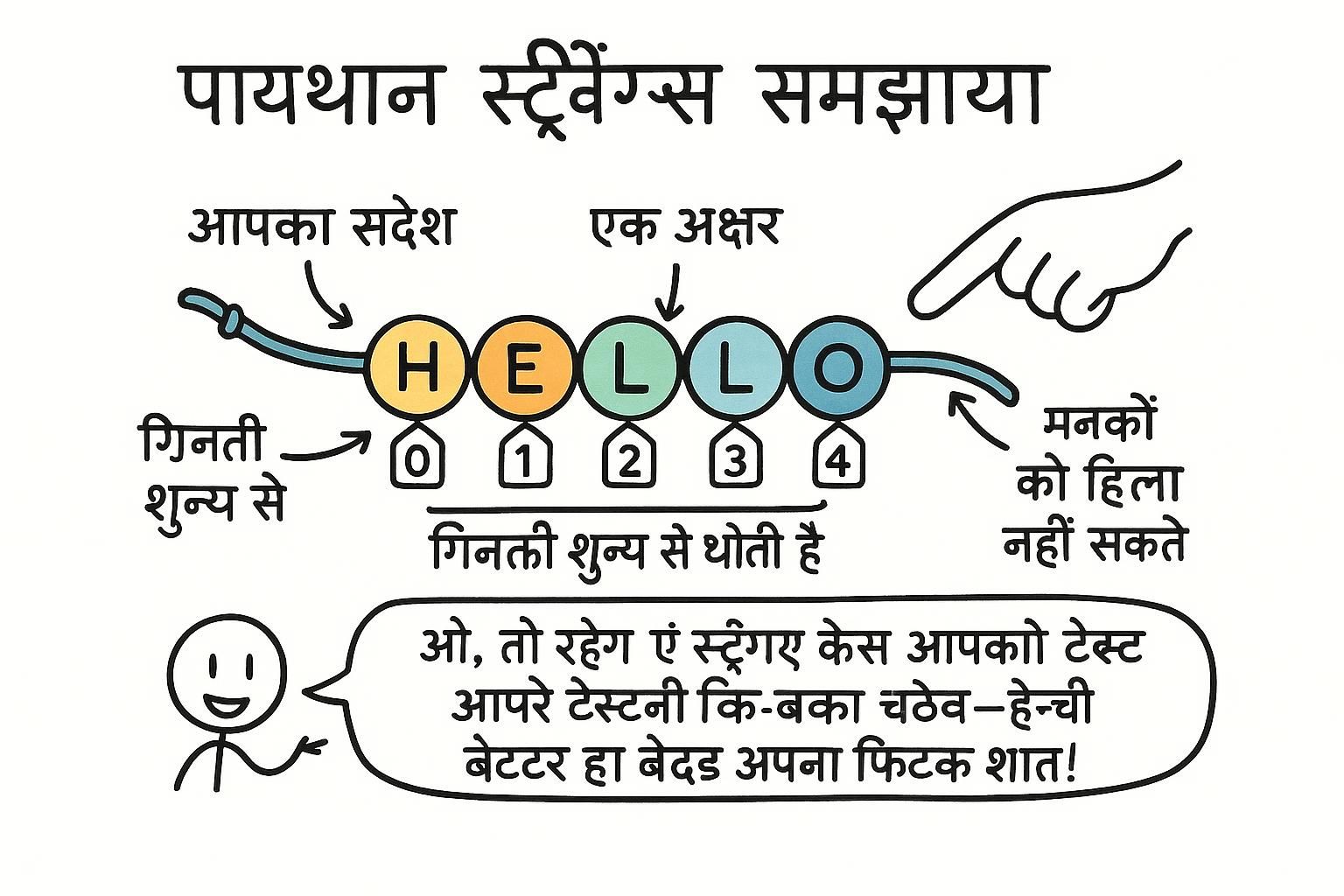
लगभग हर प्रोग्राम जो आप लिखते हैं उसमें टेक्स्ट दिखाई देता है। नाम, संदेश, स्कोर, लेबल। Python में, टेक्स्ट का कोई भी हिस्सा स्ट्रिंग कहलाता है: कोई भी मान जिसे आप कोट मार्क्स में लपेटते हैं। एकल या दोहरे, दोनों समान तरीके से काम करते हैं।
greeting = "Hello, world"
username = 'alice'कोट्स की चुनाव केवल तब महत्वपूर्ण होती है जब आपके टेक्स्ट में कोट मार्क्स हों। विपरीत स्टाइल का उपयोग करें ताकि आपको उन्हें एस्केप न करना पड़े:
note = "It's a great day" # apostrophe inside, use double quotes
message = 'She said "hello"' # double quotes inside, use single quotes
escaped = "She said \"hello\"" # or escape with a backslashअपरिवर्तनीयता
स्ट्रिंग्स अपरिवर्तनीय होती हैं: एक बार आप इसे बनाते हैं, आप इसे बदल नहीं सकते। एक स्ट्रिंग को स्थायी रूप से ठीक समझें जब यह बनाई जाती है। कोई भी ऑपरेशन जो ऐसा दिखता है कि वह स्ट्रिंग को संशोधित कर रहा है, वास्तव में एक बिल्कुल नई स्ट्रिंग बना रहा है। मूल बिल्कुल वैसा ही रहता है।
name = "alice"
name = name.upper() # "ALICE" is a new string; "alice" is unchangedसीधा परिणाम: आप किसी विशेष स्थान पर वर्ण को बदल नहीं सकते। Python यदि आप कोशिश करेंगे तो त्रुटि उठाएगा।
name = "alice"
name[0] = "A" # TypeError: 'str' object does not support item assignmentएक संशोधित स्ट्रिंग प्राप्त करने के लिए, स्लाइसिंग या एक तरीके का उपयोग करके एक नई स्ट्रिंग बनाएं। दोनों नीचे कवर किए गए हैं।

name[0] = "A" काम नहीं करता, यह एक TypeError उठाता है। इंडेक्सिंग और स्लाइसिंग
स्ट्रिंग में हर वर्ण का एक संख्यात्मक स्थान है, शून्य से शुरू होता है। आप वर्ग कोष्ठक में स्थान संख्या रखकर अलग-अलग वर्णों को पढ़ सकते हैं। नकारात्मक संख्याएं अंत से पीछे की ओर गिनती करती हैं।
word = "Python"
# 012345
print(word[0]) # "P"
print(word[2]) # "t"
print(word[5]) # "n"
print(word[-1]) # "n" (last character)
print(word[-2]) # "o" (second to last)-1 हमेशा अंतिम वर्ण है, -2 दूसरा अंतिम है, और इसी तरह। वे तब उपयोगी होते हैं जब आप स्ट्रिंग के अंत को चाहते हैं बिना उसकी सटीक लंबाई जाने।
स्लाइसिंग एक हिस्सा निकालता है। [start:stop] start को शामिल करता है और stop को बाहर करता है:
word = "Python"
print(word[0:2]) # "Py" (positions 0 and 1)
print(word[2:]) # "thon" (position 2 to end)
print(word[:3]) # "Pyt" (start to position 2)
print(word[:]) # "Python" (a copy of the whole string)
print(word[::2]) # "Pto" (every second character)
print(word[::-1]) # "nohtyP" (reversed)तीन पैटर्न सबसे अधिक पहुंचने योग्य: word[:n] पहले n वर्णों के लिए, word[n:] स्थान n से सब कुछ, word[-n:] अंतिम n वर्णों के लिए। word[::-1] एक स्ट्रिंग को उलट देता है। यह पहली बार अजीब दिखता है, लेकिन यह प्रमाणिक Python है और आप इसे अक्सर देखेंगे।
word[0] पहला वर्ण है और word[-1] अंतिम है। एक स्लाइस एक श्रेणी को पकड़ता है: word[start:stop] start को रखता है और stop से पहले रोकता है। word[::-1] स्ट्रिंग को उलट देता है, जो पहली बार अजीब दिखता है और फिर आप इसे हमेशा के लिए उपयोग करते हैं। आवश्यक स्ट्रिंग तरीके
स्ट्रिंग्स के साथ अंतर्निहित तरीकों का एक समूह आता है: ऑपरेशन जिन्हें आप किसी भी स्ट्रिंग मान पर सीधे कॉल करते हैं। आप स्ट्रिंग लिखते हैं (या इसे धारण करने वाला वेरिएबल), फिर एक बिंदु, फिर तरीके का नाम। हर तरीका एक नई स्ट्रिंग देता है। मूल कभी नहीं बदली जाती।
केस
text = "Hello, World"
text.lower() # "hello, world"
text.upper() # "HELLO, WORLD"
text.title() # "Hello, World" (each word capitalised)
text.capitalize() # "Hello, world" (first word only)lower() और upper() दो हैं जिन्हें आप सबसे अधिक उपयोग करेंगे। lower() विशेष रूप से टेक्स्ट की तुलना करते समय उपयोगी है: "Alice" और "alice" दोनों पक्षों पर .lower() कॉल करने के बाद एक ही चीज़ बन जाते हैं।
व्हाइटस्पेस
text = " hello "
text.strip() # "hello" (both sides)
text.lstrip() # "hello " (left only)
text.rstrip() # " hello" (right only)strip() स्ट्रिंग के दोनों सिरों से स्पेस हटाता है। आप इसे लगभग हर बार उपयोग करेंगे जब आप यूजर इनपुट या फाइल से टेक्स्ट संभालते हैं, क्योंकि stray spaces मौन विफलताओं का कारण बनती हैं: "alice" != "alice "।
खोज
text = "Hello, world"
text.find("world") # 7
text.find("Python") # -1 (not found)
text.count("l") # 3
text.startswith("Hello") # True
text.endswith("world") # Truefind() उस स्थान को देता है जहां टेक्स्ट का एक टुकड़ा आपकी स्ट्रिंग के अंदर शुरू होता है। यदि यह नहीं है, तो यह -1 देता है। startswith() और endswith() का उपयोग करें जब आप केवल परवाह करते हैं कि क्या स्ट्रिंग किसी विशिष्ट चीज़ से शुरू या समाप्त होती है।
प्रतिस्थापन
text = "Hello, world"
text.replace("world", "Python") # "Hello, Python"
text.replace("l", "L") # "HeLLo, worLd" (all occurrences)
text.replace("l", "L", 1) # "HeLlo, world" (first only)replace() टेक्स्ट के एक टुकड़े को दूसरे के लिए स्वैप करता है और आपको एक नई स्ट्रिंग देता है। मूल नहीं बदली जाती। तीसरा argument पास करें यदि आप केवल पहली occurrence को बदलना चाहते हैं।
विभाजन और जुड़ना
split() एक स्ट्रिंग को एक separator पर टुकड़ों में काटता है और उन्हें एक list के रूप में देता है। आप इसे बताते हैं कि किस पर काटना है:
csv_row = "राज,28,दिल्ली"
parts = csv_row.split(",") # ["राज", "28", "दिल्ली"]
" hello world ".split() # ["hello", "world"]split() एक list देता है, मानों का एक क्रमबद्ध अनुक्रम। उन्हें अपने Lists अध्याय मिलता है; अब के लिए उन्हें split() produces और join() consumes करने वाले भागों के अनुक्रम के रूप में मानें।
join() विपरीत करता है: यह strings के एक list को एक में संयोजित करता है। .join() से पहले वाली स्ट्रिंग प्रत्येक item के बीच रखी जाती है:
words = ["Hello", "world"]
" ".join(words) # "Hello world"
", ".join(words) # "Hello, world"
"".join(words) # "Helloworld"याद रखने के लिए pattern: separator.join(list_of_strings)। separator बाएं जाता है, list दाएं जाता है। " ".join(words) हर शब्द के बीच एक स्पेस रखता है। "".join(words) उन्हें बीच में कुछ के बिना glue करता है।
.lower() और .upper() case के लिए, .strip() stray spaces को trim करने के लिए, .find() टेक्स्ट को locate करने के लिए (यह `-1` देता है जब यह नहीं है), .replace() टेक्स्ट को स्वैप करने के लिए, और .split() के साथ sep.join() एक स्ट्रिंग को अलग करने और इसे वापस एक साथ रखने के लिए। f-स्ट्रिंग्स
f-strings values को सीधे टेक्स्ट के अंदर embed करते हैं। opening quote से पहले f रखें, फिर किसी भी वेरिएबल या expression को curly braces में लपेटें। Python जब कोड चलता है तो इसे भरता है। आप मान के बाद एक colon भी जोड़ सकते हैं कि यह कैसे प्रदर्शित होता है, इसे नियंत्रित करने के लिए।
name = "Alice"
score = 94.5
print(f"Hello, {name}!") # "Hello, Alice!"
print(f"Score: {score:.1f}%") # "Score: 94.5%"
print(f"2 + 2 = {2 + 2}") # "2 + 2 = 4"
print(f"Name: {name.upper()}") # "Name: ALICE": के बाद format spec मान को नियंत्रित करता है कि कैसे प्रदर्शित होता है:
| Spec | अर्थ | उदाहरण |
|---|---|---|
.2f | 2 दशमलव स्थान | f"{3.14159:.2f}" → "3.14" |
.0% | प्रतिशत, कोई दशमलव नहीं | f"{0.94:.0%}" → "94%" |
, | हज़ार separator | f"{1000000:,}" → "1,000,000" |
>10 | 10 chars में right-align | f"{'hi':>10}" → " hi" |
आप सबसे अधिक .2f का उपयोग करेंगे: किसी भी समय आप दशमलव दिखाते हैं और एक tidy संख्या चाहते हैं बजाय digits की एक लंबी run के। table में सब कुछ और वहां है जब आपको इसकी ज़रूरत हो। आप {} के अंदर कोई भी वेरिएबल, arithmetic, या method call रख सकते हैं।
:.2f two decimal places के लिए वह है जिस पर आप lean करेंगे। `+` के साथ टेक्स्ट को glue करने से बहुत ज़्यादा tidier। मल्टीलाइन स्ट्रिंग्स
एक स्ट्रिंग लिखने के लिए जो एक से अधिक lines में फैली हो, triple quote marks का उपयोग करें: शुरुआत में तीन " और अंत में तीन। Python सभी line breaks और spacing को ठीक उसी तरह preserve करता है जैसे आपने उन्हें लिखा।
message = """
Dear Alice,
Thank you for your order.
Best regards,
The Team
"""एस्केप sequences
कुछ वर्ण एक स्ट्रिंग के अंदर सीधे type करना कठिन होते हैं। Python escape sequences का उपयोग करता है: एक backslash जो कुछ के लिए खड़ा एक letter द्वारा पीछा किया। दो आप लगातार उपयोग करेंगे \n एक नई line के लिए और \t एक tab के लिए।
| Sequence | वर्ण |
|---|---|
\n | Newline |
\t | Tab |
\\ | Literal backslash |
\" | Double quote |
\' | Single quote |
print("Line one\nLine two") # two lines of output
print("Name:\tAlice") # Name: Alice
path = r"C:\Users\Alice\Documents" # raw string, no escape processingस्ट्रिंग कंटेंट्स को check करना
Python के पास methods हैं जो yes/no प्रश्न स्ट्रिंग में क्या contains है के बारे में उत्तर देते हैं। वे True या False देते हैं। सबसे उपयोगी जल्दी: isdigit() आपको check करने देता है कि क्या एक स्ट्रिंग सभी numbers है convert करने से पहले, तो आप unexpected input पर एक crash avoid कर सकते हैं।
"42".isdigit() # True
"hello".isalpha() # True
"hello42".isalnum() # True
" ".isspace() # True
"Hello".islower() # False
"HELLO".isupper() # Trueव्यावहारिक रूप से
Whitespace को strip करें, case को normalize करें, फिर जो आपको चाहिए उसे pull out करें। यह sequence लगभग किसी भी यूजर-provided text को संभालता है:
raw_input = " [email protected] "
email = raw_input.strip().lower() # "[email protected]"
at_pos = email.find("@")
username = email[:at_pos]
domain = email[at_pos + 1:]
print(f"User: {username}") # "alice"
print(f"Domain: {domain}") # "example.com"Method संदर्भ
| Method | यह क्या करता है |
|---|---|
.lower() / .upper() | सभी lowercase / सभी uppercase में convert करें |
.title() / .capitalize() | हर word को capitalize करें / केवल पहले को |
.strip() / .lstrip() / .rstrip() | Surrounding whitespace हटाएं |
.find(sub) | पहली मिलान का index, या -1 |
.count(sub) | कितनी बार sub appear होता है |
.startswith(s) / .endswith(s) | Prefix / suffix check |
.replace(old, new) | Occurrences को replace करें |
.split(sep) | एक list में split करें |
sep.join(iterable) | Items को एक स्ट्रिंग में join करें |
.isdigit() / .isalpha() / .isalnum() | Character type checks |