Strings
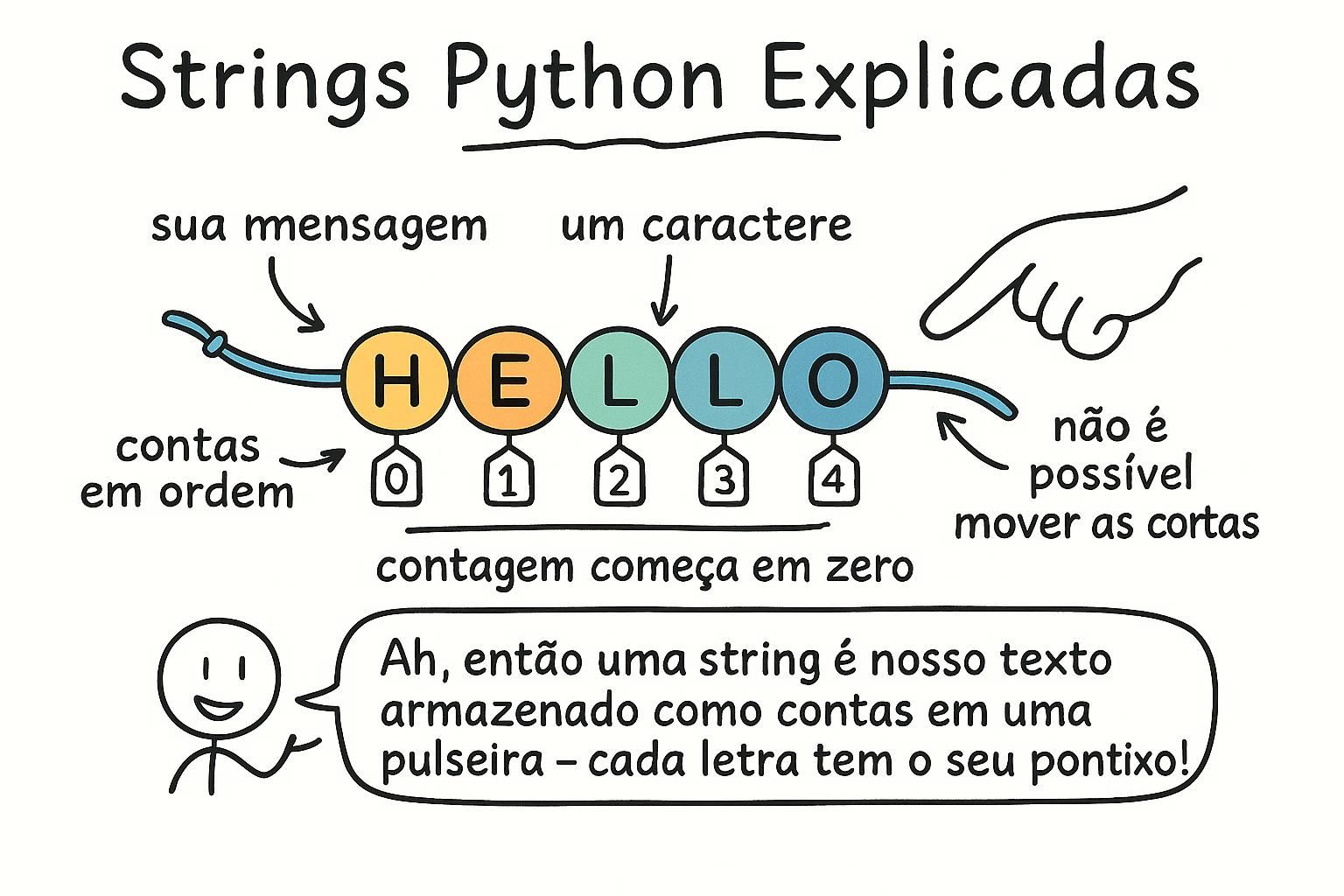
Texto aparece em quase todo programa que você escreve. Nomes, mensagens, pontuações, rótulos. Em Python, qualquer pedaço de texto é chamado de string: qualquer valor que você coloca entre aspas. Aspas simples ou duplas, ambas funcionam da mesma forma.
greeting = "Hello, world"
username = 'joao'A única vez que a escolha de aspas importa é quando seu texto contém marcas de aspas. Use o estilo oposto para não precisar escapá-las:
note = "It's a great day" # apóstrofo dentro, use aspas duplas
message = 'She said "hello"' # aspas duplas dentro, use aspas simples
escaped = "She said \"hello\"" # ou escape com uma barra invertidaImmutability
Strings são imutáveis: uma vez criada, você não pode alterá-la. Pense em uma string como permanentemente fixa no momento em que é criada. Qualquer operação que pareça modificar uma string está na verdade produzindo uma nova. A original permanece exatamente como era.
name = "joao"
name = name.upper() # "JOAO" é uma nova string; "joao" não é alteradaA consequência direta: você não pode alterar um caractere em uma posição específica. Python levantará um erro se você tentar.
name = "joao"
name[0] = "J" # TypeError: 'str' object does not support item assignmentPara obter uma string modificada, construa uma nova usando fatiamento ou um método. Ambos são cobertos abaixo.

name[0] = "J" não funciona, levanta um TypeError. Indexing and slicing
Todo caractere em uma string tem uma posição numerada, começando em zero. Você pode ler caracteres individuais colocando esse número de posição entre colchetes. Números negativos contam para trás a partir do final.
word = "Python"
# 012345
print(word[0]) # "P"
print(word[2]) # "t"
print(word[5]) # "n"
print(word[-1]) # "n" (último caractere)
print(word[-2]) # "o" (penúltimo)-1 é sempre o último caractere, -2 o penúltimo, e assim por diante. Eles são úteis quando você quer o final de uma string sem conhecer seu comprimento exato.
Fatiamento extrai um pedaço. [start:stop] inclui start e exclui stop:
word = "Python"
print(word[0:2]) # "Py" (posições 0 e 1)
print(word[2:]) # "thon" (posição 2 até o final)
print(word[:3]) # "Pyt" (início até a posição 2)
print(word[:]) # "Python" (cópia de toda a string)
print(word[::2]) # "Pto" (cada segundo caractere)
print(word[::-1]) # "nohtyP" (invertida)Três padrões principais: word[:n] para os primeiros n caracteres, word[n:] para tudo a partir da posição n em diante, word[-n:] para os últimos n caracteres. word[::-1] inverte uma string. Parece estranho na primeira vez, mas é Python idiomático e você verá frequentemente.
word[0] é o primeiro caractere e word[-1] é o último. Um fatiamento pega um intervalo: word[start:stop] mantém start e para bem antes de stop. word[::-1] inverte a string, o que parece estranho na primeira vez e depois você o usa para sempre. Essential string methods
Strings vêm com um conjunto de métodos integrados: operações que você chama diretamente em qualquer valor de string. Você escreve a string (ou a variável que a contém), depois um ponto, depois o nome do método. Cada método retorna uma nova string. O original nunca é alterado.
Case
text = "Hello, World"
text.lower() # "hello, world"
text.upper() # "HELLO, WORLD"
text.title() # "Hello, World" (cada palavra capitalizada)
text.capitalize() # "Hello, world" (apenas a primeira palavra)lower() e upper() são os dois que você mais usará. lower() é particularmente útil ao comparar texto: "Alice" e "alice" se tornam a mesma coisa uma vez que você chama .lower() em ambos os lados.
Whitespace
text = " hello "
text.strip() # "hello" (ambos os lados)
text.lstrip() # "hello " (apenas esquerda)
text.rstrip() # " hello" (apenas direita)strip() remove espaços de ambas as extremidades de uma string. Você a usará quase sempre que lidar com entrada do usuário ou texto de um arquivo, porque espaços errantes causam falhas silenciosas: "joao" != "joao ".
Finding
text = "Hello, world"
text.find("world") # 7
text.find("Python") # -1 (não encontrado)
text.count("l") # 3
text.startswith("Hello") # True
text.endswith("world") # Truefind() retorna a posição onde um pedaço de texto começa dentro de sua string. Se não estiver lá, retorna -1. Use startswith() e endswith() quando você apenas se importa se a string começa ou termina com algo específico.
Replacing
text = "Hello, world"
text.replace("world", "Python") # "Hello, Python"
text.replace("l", "L") # "HeLLo, worLd" (todas as ocorrências)
text.replace("l", "L", 1) # "HeLlo, world" (apenas a primeira)replace() troca toda ocorrência de um pedaço de texto por outro e entrega uma nova string. O original não é alterado. Passe um terceiro argumento se você apenas quer substituir a primeira ocorrência.
Splitting and joining
split() corta uma string em pedaços em um separador e retorna como uma lista. Você diz a ela o que cortar:
csv_row = "Joao,28,Brasilia"
parts = csv_row.split(",") # ["Joao", "28", "Brasilia"]
" hello world ".split() # ["hello", "world"]split() retorna uma lista, uma sequência ordenada de valores. Eles têm seu próprio capítulo Lists; por enquanto trate-os como a sequência de partes que split() produz e join() consome.
join() faz o inverso: combina uma lista de strings em uma. A string antes de .join() é colocada entre cada item:
words = ["Hello", "world"]
" ".join(words) # "Hello world"
", ".join(words) # "Hello, world"
"".join(words) # "Helloworld"O padrão a lembrar: separator.join(list_of_strings). O separador fica à esquerda, a lista à direita. " ".join(words) coloca um espaço entre cada palavra. "".join(words) as cola com nada entre.
.lower() e .upper() para caso, .strip() para aparar espaços errantes, .find() para localizar texto (retorna -1 quando não está lá), .replace() para trocar texto, e .split() com sep.join() para desconstruir uma string e reconstruir. f-strings
f-strings embutem valores diretamente dentro do texto. Coloque f antes da aspas de abertura, depois envolva qualquer variável ou expressão em chaves. Python a preenche quando o código roda. Você também pode adicionar dois-pontos após o valor para controlar como é exibido.
name = "Joao"
score = 94.5
print(f"Hello, {name}!") # "Hello, Joao!"
print(f"Score: {score:.1f}%") # "Score: 94.5%"
print(f"2 + 2 = {2 + 2}") # "2 + 2 = 4"
print(f"Name: {name.upper()}") # "Name: JOAO"A especificação de formato após : controla como o valor é exibido:
| Spec | Meaning | Example |
|---|---|---|
.2f | 2 casas decimais | f"{3.14159:.2f}" → "3.14" |
.0% | percentual, sem decimais | f"{0.94:.0%}" → "94%" |
, | separador de milhares | f"{1000000:,}" → "1,000,000" |
>10 | alinhar à direita em 10 chars | f"{'oi':>10}" → " oi" |
Você usará .2f mais: sempre que exibir um decimal e quiser um número arrumado em vez de uma longa série de dígitos. Tudo mais na tabela está lá quando você precisa. Você pode colocar qualquer variável, aritmética, ou chamada de método dentro de {}.
f antes da aspas de abertura, depois envolva qualquer variável, soma, ou chamada de método em {} e Python deixa o resultado cair quando a linha roda. Um dois-pontos dentro das chaves controla a aparência: :.2f para duas casas decimais é aquele em que você vai se inclinar. Muito mais arrumado que colar texto junto com +. Multiline strings
Para escrever uma string que abrange mais de uma linha, use aspas triplas: três " no início e três no final. Python preserva todas as quebras de linha e espaçamento exatamente como você os escreveu.
message = """
Dear Joao,
Thank you for your order.
Best regards,
The Team
"""Escape sequences
Alguns caracteres são difíceis de digitar diretamente dentro de uma string. Python usa sequências de escape: uma barra invertida seguida por uma letra que significa algo. Os dois que você usará constantemente são \n para uma nova linha e \t para uma aba.
| Sequence | Character |
|---|---|
\n | Nova linha |
\t | Aba |
\\ | Barra invertida literal |
\" | Aspas duplas |
\' | Aspas simples |
print("Line one\nLine two") # duas linhas de saída
print("Name:\tJoao") # Name: Joao
path = r"C:\Users\Joao\Documents" # string bruta, sem processamento de escape\n inicia uma nova linha, \t insere uma aba, \\ é uma barra invertida real. Esses dois, \n e \t, são aqueles que você realmente digitará. Coloque um r antes da aspas e barras invertidas voltam a ser simples, útil para caminhos do Windows. Checking string contents
Python tem métodos que respondem perguntas sim/não sobre o que uma string contém. Eles retornam True ou False. O mais útil no início: isdigit() permite você verificar se uma string é todos os números antes de convertê-la, então você pode evitar uma queda em entrada inesperada.
"42".isdigit() # True
"hello".isalpha() # True
"hello42".isalnum() # True
" ".isspace() # True
"Hello".islower() # False
"HELLO".isupper() # Trueis* respondem perguntas sim-ou-não e retornam True apenas quando cada caractere se encaixa. O que você usará primeiro: chame isdigit() antes de int() para se certificar que o texto realmente é um número, então entrada estranha não o quebra. In practice
Remova espaço em branco, normalize caso, depois puxe o que você precisa. Essa sequência lida com quase qualquer texto fornecido pelo usuário:
raw_input = " [email protected] "
email = raw_input.strip().lower() # "[email protected]"
at_pos = email.find("@")
username = email[:at_pos]
domain = email[at_pos + 1:]
print(f"User: {username}") # "joao"
print(f"Domain: {domain}") # "example.com"Method reference
| Method | What it does |
|---|---|
.lower() / .upper() | Converter para minúsculas / MAIÚSCULAS |
.title() / .capitalize() | Capitalizar cada palavra / apenas a primeira |
.strip() / .lstrip() / .rstrip() | Remover espaço em branco circundante |
.find(sub) | Índice da primeira correspondência, ou -1 |
.count(sub) | Quantas vezes sub aparece |
.startswith(s) / .endswith(s) | Verificação de prefixo / sufixo |
.replace(old, new) | Substituir ocorrências |
.split(sep) | Dividir em uma lista |
sep.join(iterable) | Juntar itens em uma string |
.isdigit() / .isalpha() / .isalnum() | Verificações de tipo de caractere |