Cadenas de texto
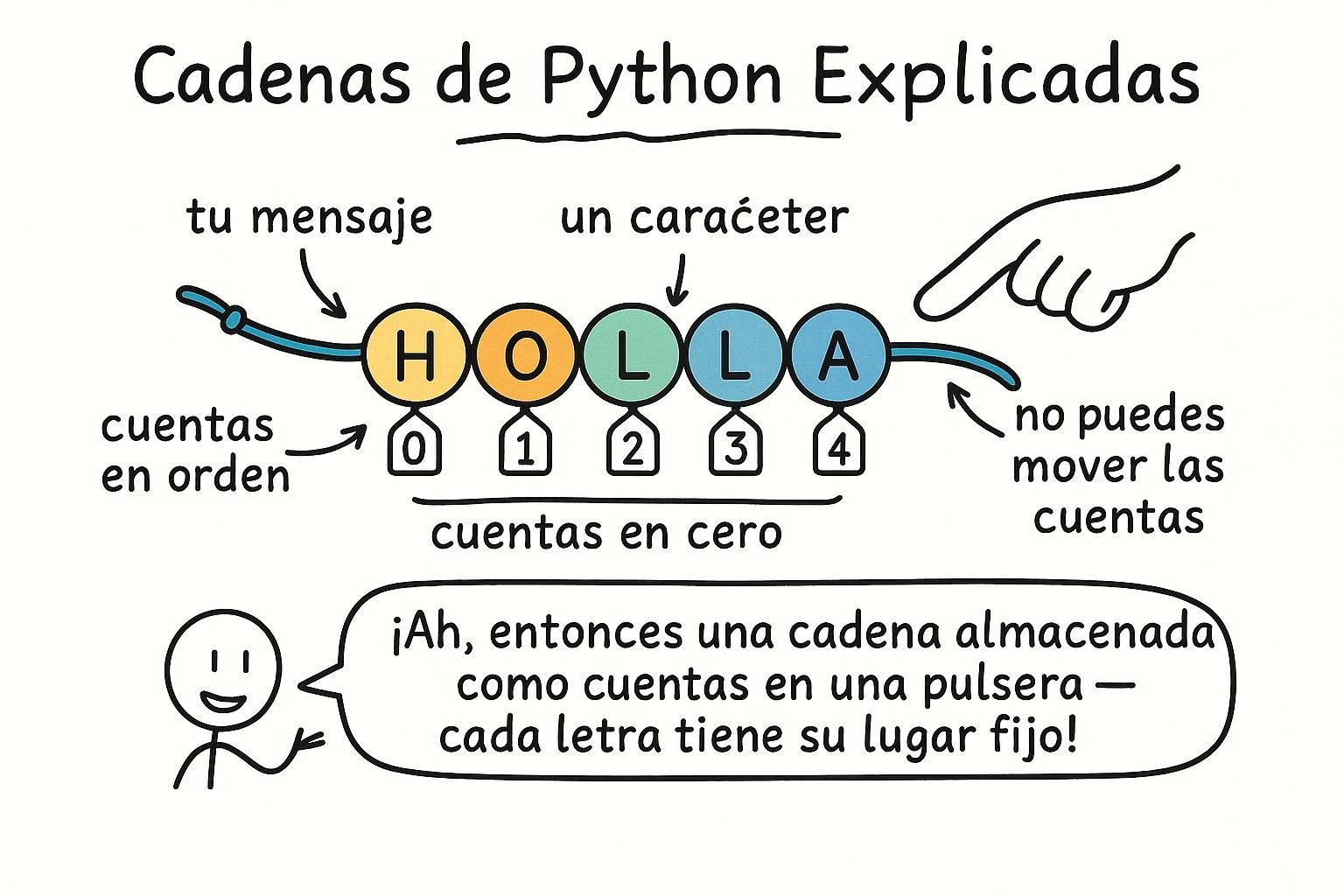
El texto aparece en casi todos los programas que escribes. Nombres, mensajes, puntuaciones, etiquetas. En Python, cualquier pieza de texto se llama cadena de texto: cualquier valor que envuelvas entre comillas. Simple o doble, ambas funcionan de la misma manera.
greeting = "Hola, mundo"
username = 'juan'La única vez que la elección de comillas importa es cuando tu texto contiene marcas de comillas. Usa el estilo opuesto para no tener que escaparlas:
note = "Es un gran día" # apóstrofo adentro, usa comillas dobles
message = 'Él dijo "hola"' # comillas dobles adentro, usa comillas simples
escaped = "Él dijo \"hola\"" # o escapa con una barra invertidaInmutabilidad
Las cadenas de texto son inmutables: una vez que las creas, no puedes cambiarlas. Piensa en una cadena de texto como fija permanentemente en el momento en que se crea. Cualquier operación que parezca modificar una cadena de texto en realidad produce una completamente nueva. La original permanece exactamente como estaba.
name = "juan"
name = name.upper() # "JUAN" es una nueva cadena; "juan" no cambiaLa consecuencia directa: no puedes cambiar un carácter en una posición específica. Python lanzará un error si lo intentas.
name = "juan"
name[0] = "J" # TypeError: 'str' object does not support item assignmentPara obtener una cadena modificada, construye una nueva usando corte o un método. Ambos se cubren a continuación.

name[0] = "J" no funciona, lanza un TypeError. Indexación y corte
Cada carácter en una cadena de texto tiene una posición numerada, comenzando en cero. Puedes leer caracteres individuales poniendo ese número de posición entre corchetes. Los números negativos cuentan hacia atrás desde el final.
word = "Python"
# 012345
print(word[0]) # "P"
print(word[2]) # "t"
print(word[5]) # "n"
print(word[-1]) # "n" (último carácter)
print(word[-2]) # "o" (penúltimo)-1 es siempre el último carácter, -2 el penúltimo, y así sucesivamente. Son útiles cuando quieres el final de una cadena de texto sin conocer su longitud exacta.
El corte extrae un trozo. [start:stop] incluye start y excluye stop:
word = "Python"
print(word[0:2]) # "Py" (posiciones 0 y 1)
print(word[2:]) # "thon" (posición 2 al final)
print(word[:3]) # "Pyt" (inicio a posición 2)
print(word[:]) # "Python" (una copia de toda la cadena)
print(word[::2]) # "Pto" (cada segundo carácter)
print(word[::-1]) # "nohtyP" (invertido)Tres patrones a los que recurrir más: word[:n] para los primeros n caracteres, word[n:] para todo desde la posición n en adelante, word[-n:] para los últimos n caracteres. word[::-1] invierte una cadena de texto. Se ve extraño la primera vez, pero es Python idiomático y lo verás a menudo.
word[0] es el primer carácter y word[-1] es el último. Un corte agarra un rango: word[start:stop] mantiene start y se detiene justo antes de stop. word[::-1] invierte la cadena de texto, que se ve extraño la primera vez y luego lo usas para siempre. Métodos esenciales de cadena de texto
Las cadenas de texto vienen con un conjunto de métodos incorporados: operaciones que llamas directamente en cualquier valor de cadena de texto. Escribes la cadena de texto (o la variable que la contiene), luego un punto, luego el nombre del método. Cada método devuelve una nueva cadena de texto. La original nunca cambia.
Caso
text = "Hola, Mundo"
text.lower() # "hola, mundo"
text.upper() # "HOLA, MUNDO"
text.title() # "Hola, Mundo" (cada palabra capitalizada)
text.capitalize() # "Hola, mundo" (solo la primera palabra)lower() y upper() son los dos que usarás más. lower() es particularmente útil cuando comparas texto: "Juan" y "juan" se vuelven lo mismo una vez que llamas .lower() en ambos lados.
Espacios en blanco
text = " hola "
text.strip() # "hola" (ambos lados)
text.lstrip() # "hola " (solo izquierda)
text.rstrip() # " hola" (solo derecha)strip() elimina espacios de ambos extremos de una cadena de texto. La usarás casi cada vez que manejes entrada del usuario o texto de un archivo, porque los espacios extraviados causan fallos silenciosos: "juan" != "juan ".
Búsqueda
text = "Hola, mundo"
text.find("mundo") # 6
text.find("Python") # -1 (no encontrado)
text.count("l") # 2
text.startswith("Hola") # True
text.endswith("mundo") # Truefind() devuelve la posición donde comienza una pieza de texto dentro de tu cadena de texto. Si no está ahí, devuelve -1. Usa startswith() y endswith() cuando solo te importe si la cadena comienza o termina con algo específico.
Reemplazo
text = "Hola, mundo"
text.replace("mundo", "Python") # "Hola, Python"
text.replace("l", "L") # "HoLa, mundo" (todas las ocurrencias)
text.replace("l", "L", 1) # "HoLa, mundo" (solo la primera)replace() intercambia cada ocurrencia de una pieza de texto por otra y te devuelve una nueva cadena de texto. La original no cambia. Pasa un tercer argumento si solo quieres reemplazar la primera ocurrencia.
División y unión
split() corta una cadena de texto en piezas en un separador y las devuelve como una lista. Le dices en qué cortar:
csv_row = "María,28,Madrid"
parts = csv_row.split(",") # ["María", "28", "Madrid"]
" hola mundo ".split() # ["hola", "mundo"]split() devuelve una lista, una secuencia ordenada de valores. Reciben su propio capítulo en Listas; por ahora trátala como la secuencia de partes que split() produce y join() consume.
join() hace lo opuesto: combina una lista de cadenas de texto en una. La cadena de texto antes de .join() se coloca entre cada elemento:
words = ["Hola", "mundo"]
" ".join(words) # "Hola mundo"
", ".join(words) # "Hola, mundo"
"".join(words) # "Holamundo"El patrón a recordar: separator.join(list_of_strings). El separador va a la izquierda, la lista a la derecha. " ".join(words) pone un espacio entre cada palabra. "".join(words) las pega sin nada entre medio.
.lower() y .upper() para caso, .strip() para recortar espacios extraviados, .find() para ubicar texto (devuelve -1 cuando no está), .replace() para intercambiar texto, y .split() con sep.join() para desmontar una cadena de texto y armarla de nuevo. f-strings
Las f-strings incrustan valores directamente dentro del texto. Pon f antes de la comilla de apertura, luego envuelve cualquier variable o expresión entre llaves. Python lo completa cuando se ejecuta el código. También puedes agregar dos puntos después del valor para controlar cómo se muestra.
name = "Juan"
score = 94.5
print(f"¡Hola, {name}!") # "¡Hola, Juan!"
print(f"Puntuación: {score:.1f}%") # "Puntuación: 94.5%"
print(f"2 + 2 = {2 + 2}") # "2 + 2 = 4"
print(f"Nombre: {name.upper()}") # "Nombre: JUAN"La especificación de formato después de : controla cómo se muestra el valor:
| Spec | Significado | Ejemplo |
|---|---|---|
.2f | 2 lugares decimales | f"{3.14159:.2f}" → "3.14" |
.0% | porcentaje, sin decimales | f"{0.94:.0%}" → "94%" |
, | separador de miles | f"{1000000:,}" → "1,000,000" |
>10 | alinear a la derecha en 10 caracteres | f"{'hola':>10}" → " hola" |
Usarás .2f la mayoría de las veces: cada vez que muestres un decimal y quieras un número ordenado en lugar de una larga serie de dígitos. Todo lo demás en la tabla está ahí cuando lo necesites. Puedes poner cualquier variable, aritmética o llamada a método dentro de {}.
f antes de la comilla de apertura, luego envuelve cualquier variable, suma o llamada a método en {} y Python deja el resultado cuando se ejecuta la línea. Una coma dentro de las llaves controla el aspecto: :.2f para dos lugares decimales es en la que te apoyarás. Mucho más limpio que pegar texto con +. Cadenas multilínea
Para escribir una cadena de texto que abarque más de una línea, usa comillas triple: tres " al principio y tres al final. Python preserva todos los saltos de línea y espaciado exactamente como los escribiste.
message = """
Estimado Juan,
Gracias por tu pedido.
Saludos cordiales,
El Equipo
"""Secuencias de escape
Algunos caracteres son difíciles de escribir directamente dentro de una cadena de texto. Python usa secuencias de escape: una barra invertida seguida de una letra que representa algo. Las dos que usarás constantemente son \n para una nueva línea y \t para una tabulación.
| Secuencia | Carácter |
|---|---|
\n | Salto de línea |
\t | Tabulación |
\\ | Barra invertida literal |
\" | Comilla doble |
\' | Comilla simple |
print("Línea uno\nLínea dos") # dos líneas de salida
print("Nombre:\tJuan") # Nombre: Juan
path = r"C:\Usuarios\Juan\Documentos" # cadena cruda, sin procesamiento de escape\n comienza una nueva línea, \t inserta una tabulación, \\ es una barra invertida real. Esos dos, \n y \t, son los que realmente escribirás. Coloca una r antes de la comilla y las barras invertidas vuelven a ser simples, útil para rutas de Windows. Verificación del contenido de cadena de texto
Python tiene métodos que responden preguntas de sí/no sobre lo que contiene una cadena de texto. Devuelven True o False. El más útil al principio: isdigit() te permite verificar si una cadena de texto es solo números antes de convertirla, para que puedas evitar un fallo en entrada inesperada.
"42".isdigit() # True
"hola".isalpha() # True
"hola42".isalnum() # True
" ".isspace() # True
"Hola".islower() # False
"HOLA".isupper() # Trueis* responden preguntas de sí o no y devuelven True solo cuando cada carácter se ajusta. El que usarás primero: llama isdigit() antes de int() para asegurarte de que el texto realmente sea un número, para que la entrada extraña no te hunda. En la práctica
Elimina espaciado en blanco, normaliza mayúsculas, luego extrae lo que necesitas. Esta secuencia maneja casi cualquier texto proporcionado por el usuario:
raw_input = " [email protected] "
email = raw_input.strip().lower() # "[email protected]"
at_pos = email.find("@")
username = email[:at_pos]
domain = email[at_pos + 1:]
print(f"Usuario: {username}") # "juan"
print(f"Dominio: {domain}") # "example.com"Referencia de métodos
| Método | Qué hace |
|---|---|
.lower() / .upper() | Convertir a minúsculas / mayúsculas |
.title() / .capitalize() | Capitalizar cada palabra / solo la primera |
.strip() / .lstrip() / .rstrip() | Eliminar espaciado en blanco circundante |
.find(sub) | Índice de primera coincidencia, o -1 |
.count(sub) | Cuántas veces aparece sub |
.startswith(s) / .endswith(s) | Verificación de prefijo / sufijo |
.replace(old, new) | Reemplazar ocurrencias |
.split(sep) | Dividir en una lista |
sep.join(iterable) | Unir elementos en una cadena de texto |
.isdigit() / .isalpha() / .isalnum() | Verificaciones de tipo de carácter |