Tuplas y conjuntos
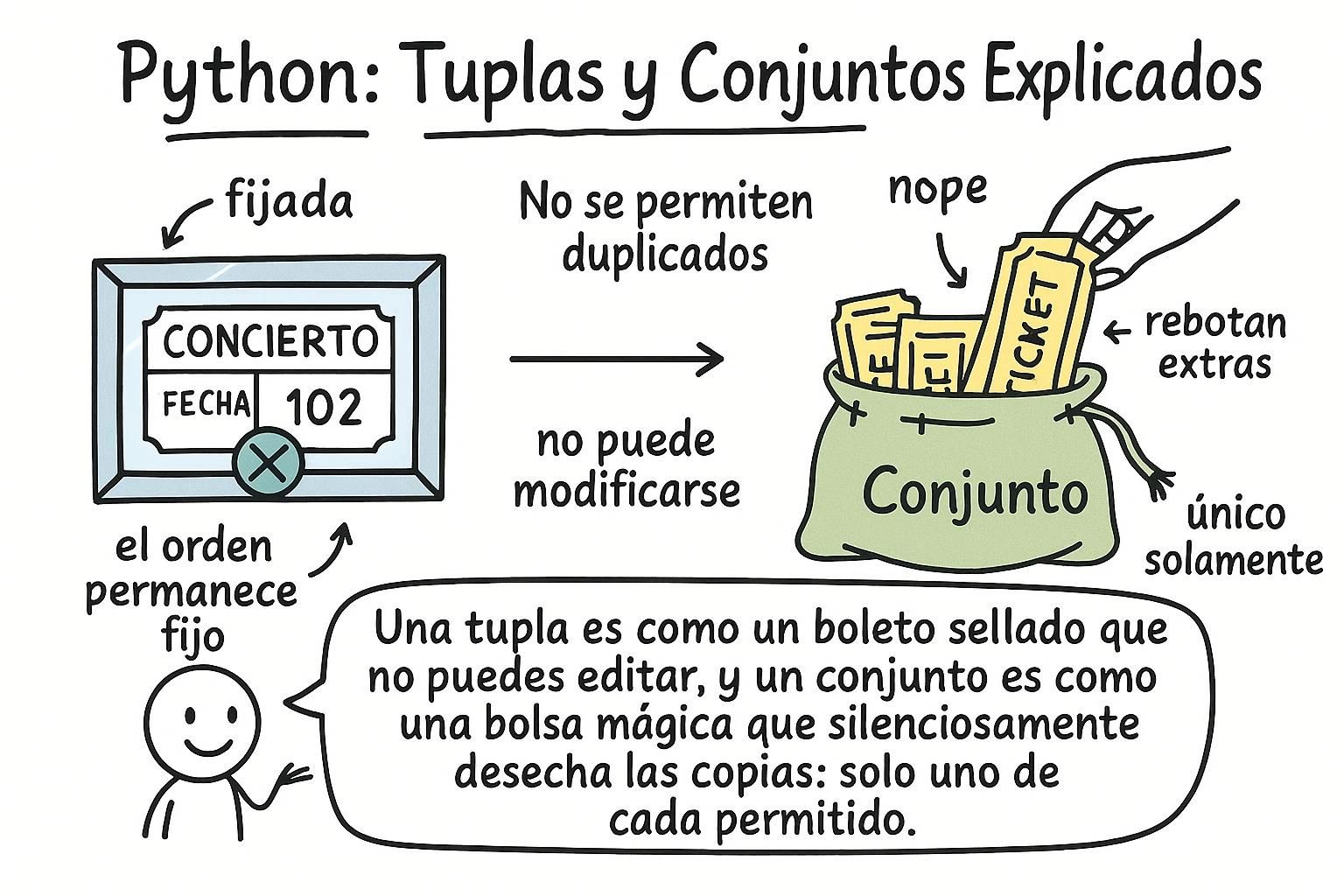
Ya conoces las listas. Python tiene dos tipos de colección más que resuelven problemas que las listas no pueden. Las tuplas mantienen un grupo fijo de valores que nunca cambiarán. Los conjuntos contienen solo valores únicos y te permiten verificar la pertenencia al instante sin importar cuán grande sea la colección.
Tuplas
Una tupla es un grupo ordenado de valores que no puede cambiar después de crearla. Los paréntesis definen una tupla, pero son opcionales. La coma es lo que realmente hace que sea una tupla. Una tupla de un solo elemento requiere una coma final.
point = (10, 20)
rgb = (255, 128, 0)
dimensions = (1920, 1080)
single = (42,) # coma final requerida para una tupla de un elemento
also_tuple = 42, 99 # los paréntesis son opcionales; la coma hace que sea una tuplaEl acceso por índice funciona exactamente como una lista. Intentar cambiar un elemento lanza un TypeError:
point = (10, 20)
point[0] # 10
point[1] # 20
point[-1] # 20
point[0] = 99 # TypeError: 'tuple' object does not support item assignment
(42,) necesita esa solitaria coma final. Intenta reasignar un elemento y obtendrás un TypeError, y esa sensación de bloqueo es exactamente por qué elegirías una tupla. Cuándo usar una tupla
Usa una tupla cuando tengas un pequeño grupo de valores relacionados que pertenezcan juntos y no cambiarán. Coordenadas (x, y), un color (r, g, b), un par nombre-puntuación ("Carlos", 87). La estructura fija señala a cualquiera que lea el código que este grupo se trata como una unidad única.
(r, g, b), un par nombre-y-puntuación. Debido a que las tuplas son hashables, incluso puedes usar una como clave de diccionario. Una lista no puede hacer eso, lo que sorprende a la gente la primera vez que lo intenta. locations = {}
locations[(40, -74)] = "Nueva York" # tupla como clave de diccionario, funciona
locations[[40, -74]] = "Nueva York" # lista como clave de diccionario, TypeErrorDesempaquetación
La desempaquetación extrae valores de una tupla y asigna cada uno a su propio nombre en una sola línea. El número de nombres debe coincidir con el número de valores. Usa * para capturar los elementos restantes en una lista.
x, y = point. El número de nombres tiene que coincidir con el número de valores, a menos que agregues *rest para recopilar lo que queda. Me hizo clic el día en que dejé de escribir point[0] y point[1] en todas partes. point = (10, 20)
x, y = point
print(x) # 10
print(y) # 20
first, *rest = [1, 2, 3, 4, 5]
# first = 1, rest = [2, 3, 4, 5]
head, *middle, tail = [1, 2, 3, 4, 5]
# head = 1, middle = [2, 3, 4], tail = 5Tuplas con nombre
Una tupla con nombre es una tupla donde cada posición tiene un nombre. En lugar de recordar que point[0] es la coordenada x, escribes point.x. Los valores siguen siendo inmutables; obtienes nombres de atributo legibles en lugar de posiciones numéricas.
point.x en lugar de recordar que point[0] es la x. Sigue siendo completamente inmutable y actúa como una tupla normal en todo lo demás. Tu yo futuro leyendo el código te lo agradecerá por los nombres. namedtuple vive en la biblioteca estándar, por lo que necesita una importación primero: from collections import namedtuple. Las importaciones reciben tratamiento completo en el capítulo Módulos.
from collections import namedtuple
Point = namedtuple("Point", ["x", "y"])
Player = namedtuple("Player", ["name", "score", "level"])
p = Point(10, 20)
p.x # 10
p.y # 20
carlos = Player("Carlos", 87, 5)
carlos.name # "Carlos"
carlos.score # 87Conjuntos
Un conjunto es una colección de valores únicos sin orden garantizado. Agregar el mismo valor dos veces no hace nada: un conjunto mantiene solo una copia de cada elemento. Usa llaves para un conjunto con elementos, o set() para crear un conjunto vacío.
set() para uno vacío, porque {} es secretamente un diccionario vacío. Ese último detalle atrapa a casi todos. tags = {"python", "beginner", "tutorial"}
numbers = {1, 2, 3, 4, 5}
empty = set() # NO {} (eso es un diccionario vacío)Agregar el mismo valor dos veces no cambia el conjunto:
tags.add("python") # tags no cambia, "python" ya está en élCuándo usar un conjunto
Los conjuntos son la herramienta correcta para tres cosas: eliminar duplicados de una lista, verificar rápidamente si algo está en una colección grande y comparar dos grupos para encontrar lo que comparten o en qué difieren.
# Eliminar duplicados de una lista
raw = ["gato", "perro", "gato", "pájaro", "perro", "gato"]
unique = list(set(raw)) # ["gato", "perro", "pájaro"] (orden no garantizado)# Verificación de pertenencia rápida
valid_codes = {"USD", "EUR", "GBP", "JPY"}
code = "EUR"
if code in valid_codes: # búsqueda instantánea, incluso con miles de códigos
print("Válido")Operaciones de conjuntos
Los conjuntos admiten las mismas operaciones que aprendiste en matemáticas: unión (todo en cualquiera de los conjuntos), intersección (solo lo que ambos conjuntos comparten) y diferencia (lo que uno tiene que el otro no). Python usa símbolos de operador para estos, y cada uno tiene un equivalente de método.
a = {1, 2, 3, 4}
b = {3, 4, 5, 6}
a | b # {1, 2, 3, 4, 5, 6} (unión: todo en cualquiera)
a & b # {3, 4} (intersección: solo en ambos)
a - b # {1, 2} (diferencia: en a pero no en b)
b - a # {5, 6} (diferencia al revés)
a ^ b # {1, 2, 5, 6} (diferencia simétrica: en uno pero no en ambos)Estos también tienen formas de método: .union(), .intersection(), .difference(), .symmetric_difference().
Modificar conjuntos
Los conjuntos son mutables. .add() agrega un elemento. .update() agrega varios a la vez de cualquier lista u otro iterable. .remove() elimina un elemento pero lanza un error si no está ahí. .discard() elimina silenciosamente si el elemento existe y no hace nada si no existe.
.add() coloca un elemento, .update() agrega un lote completo de una lista u otro iterable. El par a mantener en línea es la eliminación: .remove() produce error si el elemento no está, mientras que .discard() se encoge de hombros y sigue adelante. Cuando no estés seguro de que esté en el conjunto, .discard() te salva de un error extraño. tags = {"python", "beginner"}
tags.add("tutorial") # agrega un elemento
tags.update(["web", "api"]) # agrega múltiples elementos de cualquier iterable
tags.remove("beginner") # elimina, lanza KeyError si no se encuentra
tags.discard("missing") # elimina, sin error si no se encuentra
tags.pop() # elimina y devuelve un elemento arbitrario
tags.clear() # elimina todoUsa .discard() cuando no estés seguro de si el elemento existe.
Conjuntos congelados
Un conjunto congelado es un conjunto que no puedes modificar después de crearlo. La razón principal para usar uno: los conjuntos congelados son hashables, por lo que pueden usarse como claves de diccionario o almacenarse dentro de otros conjuntos.
valid_statuses = frozenset({"active", "paused", "deleted"})
valid_statuses.add("archived") # AttributeError, frozenset es inmutableElegir la colección correcta
Cuatro tipos, cada uno con un papel claro. Pregúntate qué necesitas hacer con los datos y la opción correcta generalmente sigue.
| list | tuple | set | dict | |
|---|---|---|---|---|
| Ordenado | Sí | Sí | No | Sí (orden de inserción) |
| Mutable | Sí | No | Sí | Sí |
| Duplicados | Sí | Sí | No | No (claves) |
| Acceso por | Índice | Índice | n/a | Clave |
| Usar cuando | Secuencia ordenada, modificable | Registro fijo | Valores únicos, pertenencia rápida | Búsqueda clave-valor |
Una regla de decisión rápida:
- ¿Necesitas buscar algo por nombre? → dict
- ¿Necesitas una colección ordenada que modificarás? → list
- ¿Tienes un grupo fijo de valores relacionados? → tuple
- ¿Necesitas valores únicos o pruebas de pertenencia rápidas? → set
En la práctica
Usando tuplas para almacenar registros fijos y un conjunto para rastrear valores únicos:
home = (51.5074, -0.1278) # latitud, longitud
office = (51.5155, -0.0922)
home_lat, home_lon = home
print(f"Hogar: {home_lat}, {home_lon}")
# Rastrear visitantes únicos con un conjunto
visitors = set()
visitors.add("carlos")
visitors.add("maría")
visitors.add("carlos") # ya está en el conjunto, silenciosamente ignorado
visitors.add("luis")
print(f"Visitantes únicos: {len(visitors)}")
print(f"carlos visitó: {'carlos' in visitors}")
print(f"juan visitó: {'juan' in visitors}")