Tuples and sets
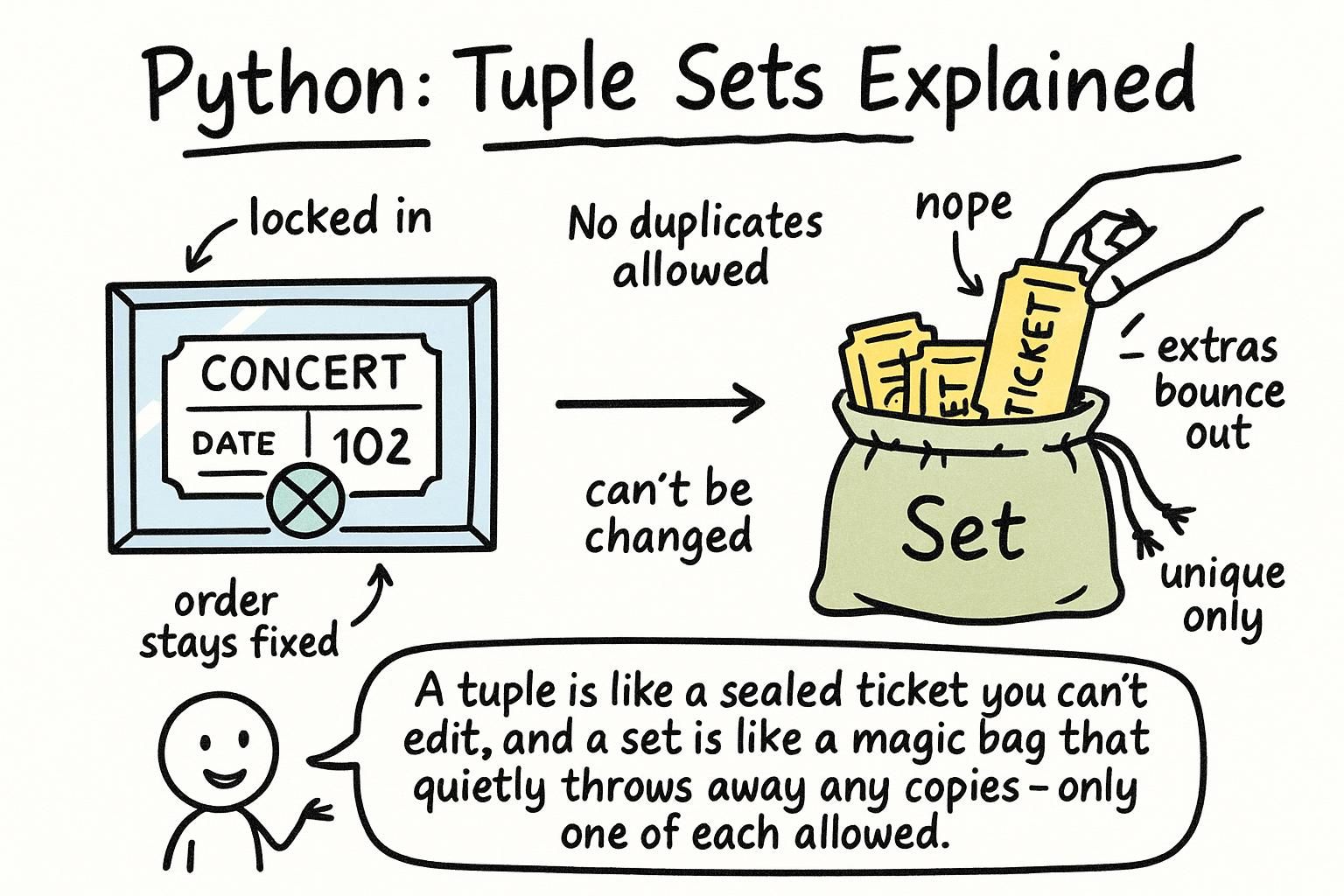
You know lists. Python has two more collection types that solve problems lists cannot. Tuples hold a fixed group of values that will never change. Sets hold only unique values and let you check membership instantly no matter how large the collection gets.
Tuples
A tuple is an ordered group of values that cannot be changed after you create it. Parentheses define a tuple, but they are optional. The comma is what actually makes it a tuple. A single-item tuple requires a trailing comma.
point = (10, 20)
rgb = (255, 128, 0)
dimensions = (1920, 1080)
single = (42,) # trailing comma required for a single-item tuple
also_tuple = 42, 99 # parentheses are optional; the comma makes it a tupleAccess by index works exactly like a list. Trying to change an item raises a TypeError:
point = (10, 20)
point[0] # 10
point[1] # 20
point[-1] # 20
point[0] = 99 # TypeError: 'tuple' object does not support item assignment
(42,) needs that lonely trailing comma. Try to reassign an item and you get a TypeError, and that locked-in feeling is exactly why you'd pick a tuple. When to use a tuple
Use a tuple when you have a small group of related values that belong together and will not change. Coordinates (x, y), a colour (r, g, b), a name-score pair ("Alice", 87). The fixed structure signals to anyone reading the code that this group is treated as a single unit.
(r, g, b) colour, a name-and-score pair. Because tuples are hashable, you can even use one as a dict key. A list can't do that, which trips people up the first time they try. locations = {}
locations[(40, -74)] = "New York" # tuple as a dict key, works
locations[[40, -74]] = "New York" # list as a dict key, TypeErrorUnpacking
Unpacking pulls values out of a tuple and assigns each to its own name in a single line. The number of names must match the number of values. Use * to capture any remaining items into a list.
x, y = point. The number of names has to match the number of values, unless you add a *rest to scoop up whatever's left over. It clicked for me the day I stopped writing point[0] and point[1] everywhere. point = (10, 20)
x, y = point
print(x) # 10
print(y) # 20
first, *rest = [1, 2, 3, 4, 5]
# first = 1, rest = [2, 3, 4, 5]
head, *middle, tail = [1, 2, 3, 4, 5]
# head = 1, middle = [2, 3, 4], tail = 5Named tuples
A named tuple is a tuple where each position has a name. Instead of remembering that point[0] is the x-coordinate, you write point.x. The values are still immutable; you get readable attribute names instead of numeric positions.
point.x instead of remembering that point[0] is the x. It's still fully immutable and acts like a regular tuple in every other way. Your future self reading the code will thank you for the names. namedtuple lives in the standard library, so it needs an import first: from collections import namedtuple. Imports get full treatment in the Modules chapter.
from collections import namedtuple
Point = namedtuple("Point", ["x", "y"])
Player = namedtuple("Player", ["name", "score", "level"])
p = Point(10, 20)
p.x # 10
p.y # 20
alice = Player("Alice", 87, 5)
alice.name # "Alice"
alice.score # 87Sets
A set is a collection of unique values with no guaranteed order. Adding the same value twice does nothing: a set keeps only one copy of each item. Use curly braces for a set with items, or set() to create an empty set.
set() for an empty one, because {} is secretly an empty dict. That last bit catches almost everyone. tags = {"python", "beginner", "tutorial"}
numbers = {1, 2, 3, 4, 5}
empty = set() # NOT {} (that's an empty dict)Adding the same value twice does not change the set:
tags.add("python") # tags is unchanged, "python" is already in itWhen to use a set
Sets are the right tool for three things: removing duplicates from a list, checking quickly whether something is in a large collection, and comparing two groups to find what they share or differ on.
# Remove duplicates from a list
raw = ["cat", "dog", "cat", "bird", "dog", "cat"]
unique = list(set(raw)) # ["cat", "dog", "bird"] (order not guaranteed)# Fast membership check
valid_codes = {"USD", "EUR", "GBP", "JPY"}
code = "EUR"
if code in valid_codes: # instant lookup, even with thousands of codes
print("Valid")Set operations
Sets support the same operations you learned in maths: union (everything in either set), intersection (only what both sets share), and difference (what one has that the other does not). Python uses operator symbols for these, and each has a method equivalent.
| is union (in either), & is intersection (in both), - is difference (in one but not the other), and ^ is symmetric difference (in one but not both). Each one also has a spelled-out method like .union() if you prefer words to symbols. a = {1, 2, 3, 4}
b = {3, 4, 5, 6}
a | b # {1, 2, 3, 4, 5, 6} (union: everything in either)
a & b # {3, 4} (intersection: only in both)
a - b # {1, 2} (difference: in a but not b)
b - a # {5, 6} (difference the other way)
a ^ b # {1, 2, 5, 6} (symmetric difference: in one but not both)These also have method forms: .union(), .intersection(), .difference(), .symmetric_difference().
Modifying sets
Sets are mutable. .add() adds one item. .update() adds several at once from any list or other iterable. .remove() deletes an item but raises an error if it is not there. .discard() deletes silently if the item exists and does nothing if it does not.
.add() puts in one item, .update() adds a whole batch from a list or other iterable. The pair to keep straight is removal: .remove() errors if the item isn't there, while .discard() shrugs and moves on. When you're not sure it's in the set, .discard() saves you a stray error. tags = {"python", "beginner"}
tags.add("tutorial") # add one item
tags.update(["web", "api"]) # add multiple items from any iterable
tags.remove("beginner") # remove, raises KeyError if not found
tags.discard("missing") # remove, no error if not found
tags.pop() # remove and return an arbitrary item
tags.clear() # remove everythingUse .discard() when you are not sure whether the item exists.
Frozen sets
A frozen set is a set you cannot modify after creation. The main reason to use one: frozen sets are hashable, so they can be used as dictionary keys or stored inside other sets.
valid_statuses = frozenset({"active", "paused", "deleted"})
valid_statuses.add("archived") # AttributeError, frozenset is immutableChoosing the right collection
Four types, each with a clear role. Ask what you need to do with the data and the right choice usually follows.
| list | tuple | set | dict | |
|---|---|---|---|---|
| Ordered | Yes | Yes | No | Yes (insertion order) |
| Mutable | Yes | No | Yes | Yes |
| Duplicates | Yes | Yes | No | No (keys) |
| Access by | Index | Index | n/a | Key |
| Use when | Ordered, changeable sequence | Fixed record | Unique values, fast membership | Key-value lookup |
A quick decision rule:
- Need to look something up by name? → dict
- Need an ordered collection you will modify? → list
- Have a fixed group of related values? → tuple
- Need unique values or fast membership tests? → set
In practice
Using tuples to store fixed records and a set to track unique values:
home = (51.5074, -0.1278) # latitude, longitude
office = (51.5155, -0.0922)
home_lat, home_lon = home
print(f"Home: {home_lat}, {home_lon}")
# Track unique visitors with a set
visitors = set()
visitors.add("alice")
visitors.add("bob")
visitors.add("alice") # already in set, silently ignored
visitors.add("carol")
print(f"Unique visitors: {len(visitors)}")
print(f"alice visited: {'alice' in visitors}")
print(f"dave visited: {'dave' in visitors}")