튜플과 집합
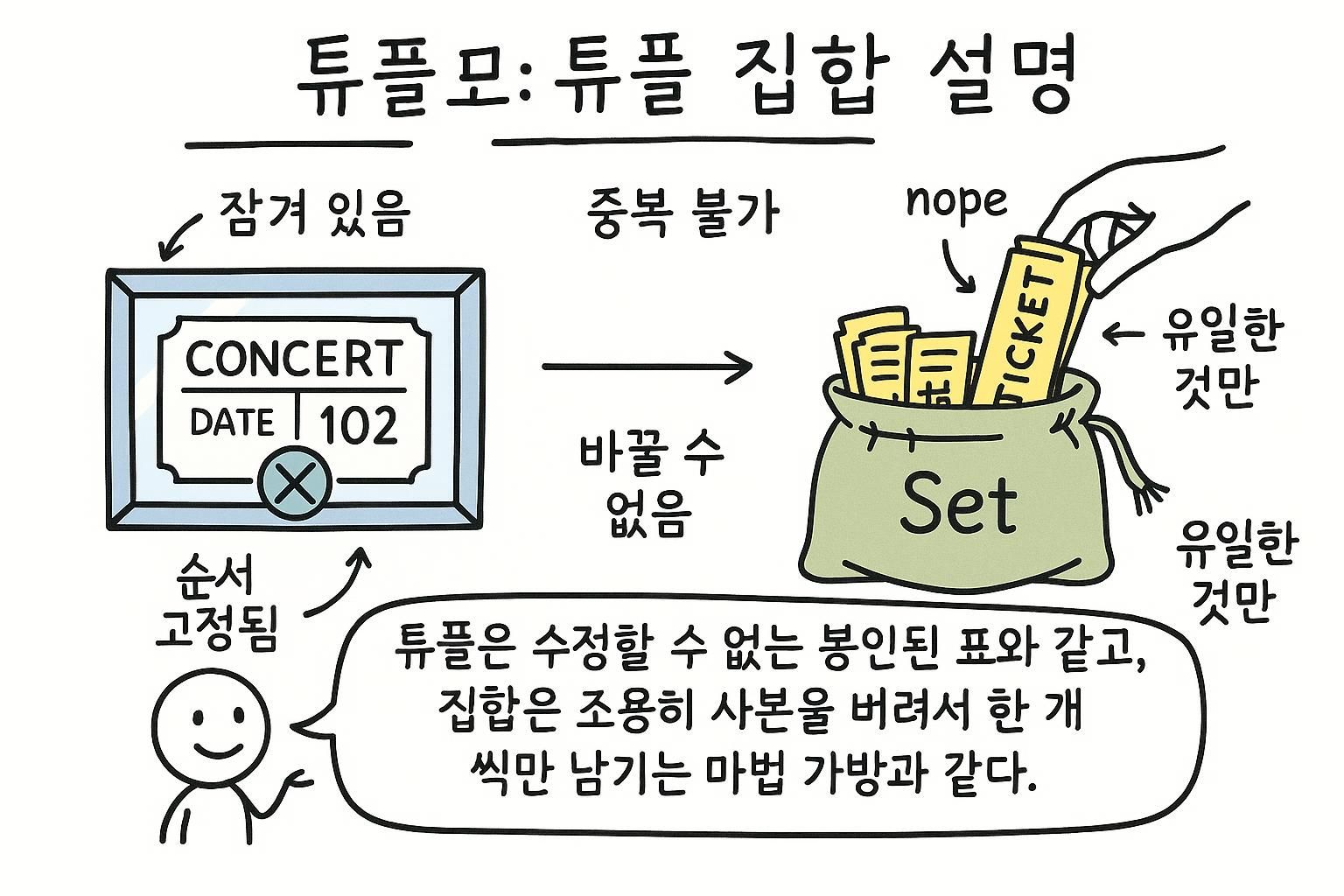
이제 리스트를 알고 있습니다. 파이썬에는 리스트로 해결할 수 없는 문제를 푸는 두 가지 컬렉션 타입이 더 있습니다. 튜플은 절대 변하지 않을 값들의 고정된 그룹을 보유합니다. 집합은 오직 고유한 값만 보유하며 컬렉션이 아무리 커도 멤버십을 즉시 확인할 수 있습니다.
튜플
튜플은 생성 후 변경할 수 없는 순서가 있는 값들의 그룹입니다. 괄호는 튜플을 정의하지만 선택 사항입니다. 쉼표가 실제로 튜플을 만드는 것입니다. 단일 항목 튜플은 끝에 쉼표가 필요합니다.
point = (10, 20)
rgb = (255, 128, 0)
dimensions = (1920, 1080)
single = (42,) # 단일 항목 튜플에 필수인 끝의 쉼표
also_tuple = 42, 99 # 괄호는 선택 사항; 쉼표가 튜플을 만듭니다인덱스로 접근하는 것은 리스트와 정확히 동일하게 작동합니다. 항목을 변경하려고 시도하면 TypeError가 발생합니다:
point = (10, 20)
point[0] # 10
point[1] # 20
point[-1] # 20
point[0] = 99 # TypeError: 'tuple' object does not support item assignment
(42,)는 그 외로운 끝의 쉼표가 필요합니다. 항목을 다시 할당하려고 시도하면 TypeError를 얻으며, 그 잠긴 느낌이 정확히 튜플을 선택하는 이유입니다. 튜플을 언제 사용할지
작은 관련 값 그룹을 가지고 있고 변하지 않을 때 튜플을 사용하세요. 좌표 (x, y), 색상 (r, g, b), 이름-점수 쌍 ("민준", 87). 고정 구조는 코드를 읽는 누구에게나 이 그룹이 단일 단위로 취급된다는 신호를 보냅니다.
(r, g, b) 색상, 이름-점수 쌍. 튜플이 해시 가능하므로 dict 키로도 사용할 수 있습니다. 리스트는 할 수 없으며, 이는 처음 시도할 때 사람들을 곤란하게 합니다. locations = {}
locations[(40, -74)] = "서울" # dict 키로서의 튜플, 작동함
locations[[40, -74]] = "서울" # dict 키로서의 리스트, TypeError언팩
언팩은 튜플에서 값을 꺼내 각각을 한 줄에서 고유한 이름에 할당합니다. 이름의 수는 값의 수와 일치해야 합니다. *를 사용하여 남은 항목들을 리스트로 캡처하세요.
point = (10, 20)
x, y = point
print(x) # 10
print(y) # 20
first, *rest = [1, 2, 3, 4, 5]
# first = 1, rest = [2, 3, 4, 5]
head, *middle, tail = [1, 2, 3, 4, 5]
# head = 1, middle = [2, 3, 4], tail = 5이름 붙은 튜플
이름 붙은 튜플은 각 위치가 이름을 가진 튜플입니다. point[0]이 x 좌표라는 것을 기억하는 대신 point.x를 작성합니다. 값은 여전히 불변입니다; 수치 위치 대신 읽을 수 있는 속성 이름을 얻습니다.
namedtuple은 표준 라이브러리에 있으므로 먼저 임포트가 필요합니다: from collections import namedtuple. 임포트는 모듈 장에서 전체 처리를 얻습니다.
from collections import namedtuple
Point = namedtuple("Point", ["x", "y"])
Player = namedtuple("Player", ["name", "score", "level"])
p = Point(10, 20)
p.x # 10
p.y # 20
alice = Player("민준", 87, 5)
alice.name # "민준"
alice.score # 87집합
집합은 보장된 순서가 없는 고유값 컬렉션입니다. 같은 값을 두 번 추가하면 아무것도 하지 않습니다: 집합은 각 항목의 복사본 하나만 유지합니다. 항목이 있는 집합에는 중괄호를 사용하거나, 빈 집합을 만들려면 set()를 사용합니다.
set()을 사용하세요. 왜냐하면 {}는 비밀스럽게 빈 딕셔너리이기 때문입니다. 그 마지막 비트는 거의 모두를 잡습니다. tags = {"python", "beginner", "tutorial"}
numbers = {1, 2, 3, 4, 5}
empty = set() # NOT {} (그것은 빈 딕셔너리입니다)같은 값을 두 번 추가하면 집합을 변경하지 않습니다:
tags.add("python") # tags가 변경되지 않음, "python"은 이미 그것에 있습니다집합을 언제 사용할지
집합은 세 가지를 위한 올바른 도구입니다: 리스트에서 중복 제거, 빠르게 큰 컬렉션에서 무언가가 있는지 확인, 두 그룹을 비교하여 공유 또는 다른 점 찾기.
# 리스트에서 중복 제거
raw = ["cat", "dog", "cat", "bird", "dog", "cat"]
unique = list(set(raw)) # ["cat", "dog", "bird"] (순서 보장되지 않음)# 빠른 멤버십 확인
valid_codes = {"USD", "EUR", "GBP", "JPY"}
code = "EUR"
if code in valid_codes: # 수천 개 코드가 있어도 즉시 조회
print("Valid")집합 연산
집합은 수학에서 배운 같은 연산을 지원합니다: 합집합(두 집합 중 하나의 모든 것), 교집합(두 집합만 공유하는 것), 그리고 차이(하나가 다른 것이 없는 것). 파이썬은 이들에 대해 연산자 기호를 사용하며 각각은 메서드 동등물을 가집니다.
|는 합집합(하나), &는 교집합(둘 다), -는 차이(하나가 아님), ^는 대칭 차이(하나가 아닌 것). 각각은 또한 기호보다 단어를 선호하면 .union() 같은 철저한 메서드를 가집니다. a = {1, 2, 3, 4}
b = {3, 4, 5, 6}
a | b # {1, 2, 3, 4, 5, 6} (합집합: 하나의 모든 것)
a & b # {3, 4} (교집합: 둘 다에만 있음)
a - b # {1, 2} (차이: a에 있지만 b에는 없음)
b - a # {5, 6} (다른 방향의 차이)
a ^ b # {1, 2, 5, 6} (대칭 차이: 하나에 있지만 둘 다에는 없음)메서드 형식도 있습니다: .union(), .intersection(), .difference(), .symmetric_difference().
집합 수정
집합은 변경 가능합니다. .add()는 항목 하나를 추가합니다. .update()는 리스트나 다른 반복 가능한 것에서 여러 개를 한 번에 추가합니다. .remove()는 항목을 삭제하지만 그것이 없으면 오류를 발생시킵니다. .discard()는 항목이 존재하면 조용히 삭제하고 그렇지 않으면 아무것도 하지 않습니다.
.add()는 항목 하나를 넣으며, .update()는 리스트나 다른 반복 가능한 것에서 전체 배치를 추가합니다. 유지할 쌍은 제거입니다: .remove()는 항목이 없으면 오류를 발생시키지만 .discard()는 쌍을 이루고 이동합니다. 당신이 그것이 집합에 있다고 확실하지 않을 때 .discard()는 당신을 미로 오류에서 구합니다. tags = {"python", "beginner"}
tags.add("tutorial") # 항목 하나 추가
tags.update(["web", "api"]) # 반복 가능한 모든 것에서 여러 항목 추가
tags.remove("beginner") # 제거, 찾지 못하면 KeyError 발생
tags.discard("missing") # 제거, 찾지 못하면 오류 없음
tags.pop() # 임의의 항목 제거 및 반환
tags.clear() # 모든 것 제거현재 항목이 있는지 확실하지 않을 때 .discard()를 사용하세요.
고정 집합
고정 집합은 생성 후 수정할 수 없는 집합입니다. 하나를 사용하는 주요 이유: 고정 집합은 해시 가능하므로 딕셔너리 키로 사용되거나 다른 집합 내부에 저장될 수 있습니다.
valid_statuses = frozenset({"active", "paused", "deleted"})
valid_statuses.add("archived") # AttributeError, frozenset은 불변입니다올바른 컬렉션 선택
네 가지 타입, 각각 명확한 역할. 데이터로 무엇을 해야 하는지 물어보고 올바른 선택이 보통 따릅니다.
| list | tuple | set | dict | |
|---|---|---|---|---|
| 순서 | 예 | 예 | 아니오 | 예(삽입 순서) |
| 변경 가능 | 예 | 아니오 | 예 | 예 |
| 중복 | 예 | 예 | 아니오 | 아니오(키) |
| 접근 | 인덱스 | 인덱스 | n/a | 키 |
| 사용할 때 | 순서가 있고 변경할 시퀀스 | 고정 레코드 | 고유 값, 빠른 멤버십 | 키-값 조회 |
빠른 결정 규칙:
- 이름으로 무언가를 찾아야 합니까? → dict
- 변경할 순서가 있는 컬렉션이 필요합니까? → list
- 관련 값의 고정 그룹이 있습니까? → tuple
- 고유 값이나 빠른 멤버십 테스트가 필요합니까? → set
실제로
고정 레코드를 저장하는 튜플과 고유 값을 추적하는 집합 사용:
home = (51.5074, -0.1278) # 위도, 경도
office = (51.5155, -0.0922)
home_lat, home_lon = home
print(f"Home: {home_lat}, {home_lon}")
# 고유 방문자를 집합으로 추적합니다
visitors = set()
visitors.add("민준")
visitors.add("소현")
visitors.add("민준") # 이미 집합에 있음, 조용히 무시됨
visitors.add("지원")
print(f"Unique visitors: {len(visitors)}")
print(f"민준 visited: {'민준' in visitors}")
print(f"현준 visited: {'현준' in visitors}")