タプルとセット
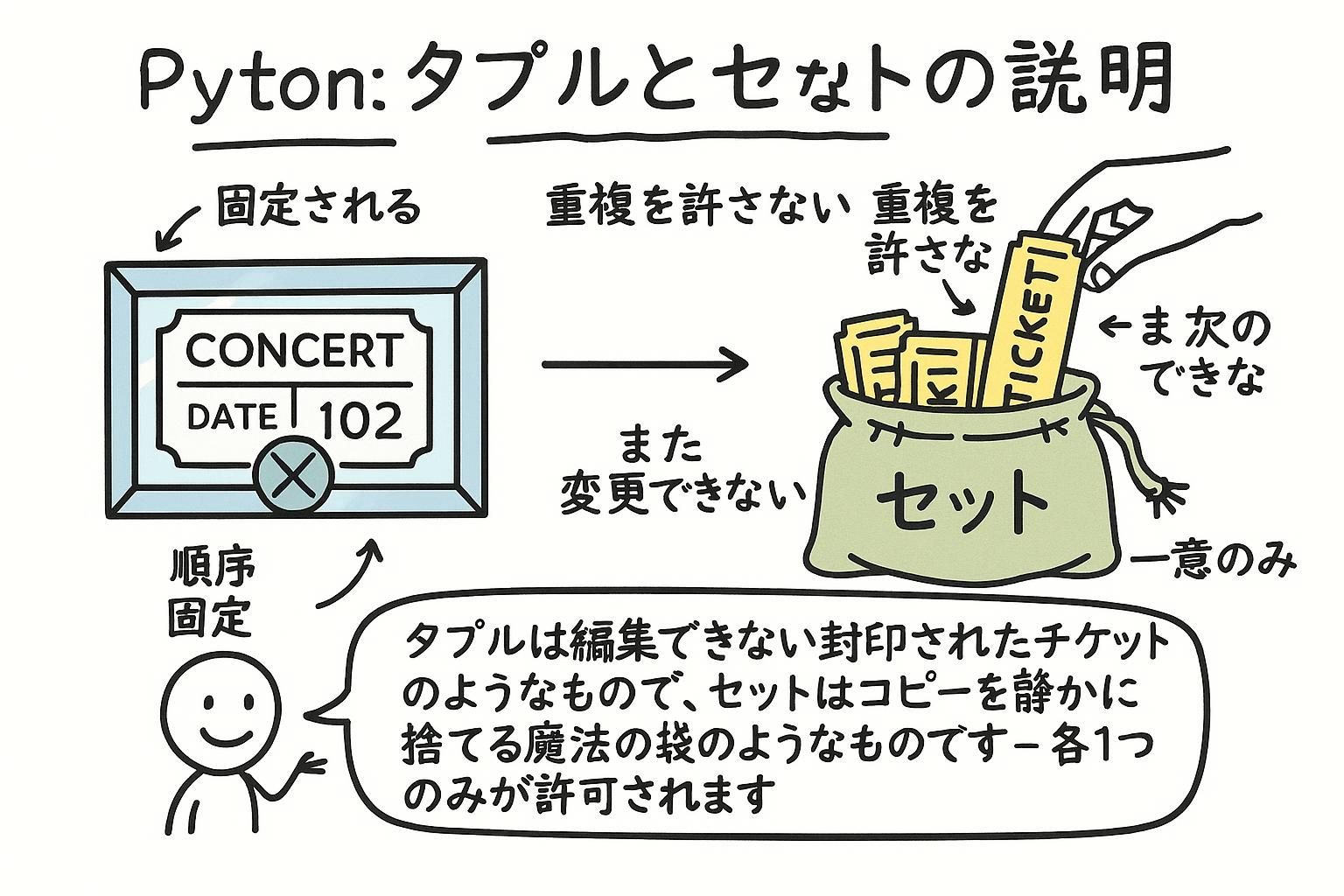
リストはご存じでしょう。Pythonには、リストでは解決できない問題を解く、2つのコレクション型があります。タプルは変わることのない値の固定グループを保持します。セットは一意の値だけを保持し、コレクションがどんなに大きくても、メンバーシップをすぐに確認できます。
タプル
タプルは、作成後に変更できない順序付けされた値のグループです。括弧がタプルを定義しますが、オプションです。実際にタプルを作成するのはカンマです。単一項目のタプルは末尾のカンマが必要です。
point = (10, 20)
rgb = (255, 128, 0)
dimensions = (1920, 1080)
single = (42,) # 単一項目タプルには末尾のカンマが必須
also_tuple = 42, 99 # 括弧はオプション;カンマがタプルを作成インデックスでのアクセスはリストとまったく同じです。項目を変更しようとするとTypeErrorが発生します:
point = (10, 20)
point[0] # 10
point[1] # 20
point[-1] # 20
point[0] = 99 # TypeError: 'tuple' object does not support item assignment
(42,)が孤立した末尾のカンマが必要な理由です。項目を再割り当てしようとすると、TypeErrorが発生します。その锁定-内感覚がまさにタプルを選ぶ理由です。 タプルを使う場合
一緒に属する関連値の小さなグループを持っていて、変わることのないときにタプルを使用します。座標(x, y)、色(r, g, b)、名前スコアペア("太郎", 87)。固定構造は、コードを読む人にこのグループが単一ユニットとして扱われていることを知らせます。
(r, g, b)色、名前とスコアペア。タプルはハッシュ可能であるため、辞書キーとして使用することもできます。リストはそうではできず、最初に試みるとき人々を困らせます。 locations = {}
locations[(40, -74)] = "東京" # 辞書キーとしてのタプル、機能
locations[[40, -74]] = "東京" # 辞書キーとしてのリスト、TypeErrorアンパッキング
アンパッキングはタプルから値を抽出し、1行で各値を独自の名前に割り当てます。名前の数は値の数と一致する必要があります。*を使用して、残りのアイテムを任意にリストにキャプチャします。
point = (10, 20)
x, y = point
print(x) # 10
print(y) # 20
first, *rest = [1, 2, 3, 4, 5]
# first = 1, rest = [2, 3, 4, 5]
head, *middle, tail = [1, 2, 3, 4, 5]
# head = 1, middle = [2, 3, 4], tail = 5名前付きタプル
名前付きタプルは、各位置に名前を持つタプルです。point[0]がx座標であることを覚える代わりに、point.xと書きます。値はまだ不変です;数値位置の代わりに、読み取り可能な属性名を取得します。
namedtupleは標準ライブラリに存在するため、最初にインポートが必要です:from collections import namedtuple。インポートはモジュールの章で完全に扱われます。
from collections import namedtuple
Point = namedtuple("Point", ["x", "y"])
Player = namedtuple("Player", ["name", "score", "level"])
p = Point(10, 20)
p.x # 10
p.y # 20
alice = Player("太郎", 87, 5)
alice.name # "太郎"
alice.score # 87セット
セットは、順序が保証されていない一意の値のコレクションです。同じ値を2回追加しても何もしません:セットは各アイテムのコピーを1つだけ保持します。セットをアイテムで使用するには中括弧を使用するか、set()を使用して空のセットを作成します。
set()に到達してください。`{}`は秘密の空の辞書だからです。最後のビットはほぼ全員をつかみます。 tags = {"python", "beginner", "tutorial"}
numbers = {1, 2, 3, 4, 5}
empty = set() # {}ではなく(それは空の辞書)同じ値を2回追加してもセットは変わりません:
tags.add("python") # tagsは変わりません、"python"は既にそこにありますセットを使う場合
セットは3つのことに対して正しいツールです:リストから重複を削除する、大きなコレクション全体で何かが存在するかどうかを素早くチェックする、2つのグループを比較して共有内容または相違点を見つける。
# リストから重複を削除
raw = ["cat", "dog", "cat", "bird", "dog", "cat"]
unique = list(set(raw)) # ["cat", "dog", "bird"](順序は保証されていない)# 高速メンバーシップチェック
valid_codes = {"USD", "EUR", "GBP", "JPY"}
code = "EUR"
if code in valid_codes: # 即座ルックアップ、数千のコードの場合でも
print("Valid")セット操作
セットは数学で学んだ同じ操作をサポートします:和(どちらかのセットに含まれているすべて)、積(両方のセットが共有するもののみ)、差(1つが他にない含まれているもの)。Pythonはこれらに対してオペレータシンボルを使用し、各メソッドの等価を持ちます。
a = {1, 2, 3, 4}
b = {3, 4, 5, 6}
a | b # {1, 2, 3, 4, 5, 6} (和:どちらかに含まれているすべて)
a & b # {3, 4} (積:両方に含まれているのみ)
a - b # {1, 2} (差:aに含まれているが b ではない)
b - a # {5, 6} (差反対方向)
a ^ b # {1, 2, 5, 6} (対称差:1つに含まれているが両方ではない)これらはまたメソッド形式を持ちます:.union()、.intersection()、.difference()、.symmetric_difference()。
セット修正
セットは可変です。.add()は1つのアイテムを追加します。.update()は任意のリストまたは他のイテラブルから一度に複数を追加します。.remove()はアイテムを削除しますがそこにない場合エラーを発生させます。.discard()はアイテムが存在する場合は静かに削除し、存在しない場合は何もしません。
tags = {"python", "beginner"}
tags.add("tutorial") # 1つのアイテムを追加
tags.update(["web", "api"]) # 任意のイテラブルから複数のアイテムを追加
tags.remove("beginner") # 削除、見つからない場合KeyErrorを発生させます
tags.discard("missing") # 削除、見つからない場合エラーなし
tags.pop() # 削除して任意のアイテムを返す
tags.clear() # すべてを削除アイテムが存在するかどうかが確実でないとき、.discard()を使用します。
フローズンセット
フローズンセットは、作成後に修正できないセットです。使用する主な理由:フローズンセットはハッシュ可能であるため、辞書キーまたは他のセット内に保存できます。
valid_statuses = frozenset({"active", "paused", "deleted"})
valid_statuses.add("archived") # AttributeError、frozenseは不変正しいコレクションを選ぶ
4つのタイプ、各々明確な役割で。何をしたい必要があるデータで尋ねてください。そして、正しい選択は通常、従います。
| list | tuple | set | dict | |
|---|---|---|---|---|
| Ordered | Yes | Yes | No | Yes (insertion order) |
| Mutable | Yes | No | Yes | Yes |
| Duplicates | Yes | Yes | No | No (keys) |
| Access by | Index | Index | n/a | Key |
| Use when | Ordered, changeable sequence | Fixed record | Unique values, fast membership | Key-value lookup |
素早い判断規則:
- 名前で何かルックアップが必要ですか? → dict
- 修正可能性を持つ順序付けられたコレクション必要ですか? → list
- 関連値の固定グループを持っていますか? → tuple
- 一意値または高速メンバーシップテストが必要ですか? → set
実践
固定レコードを保存するタプルおよび一意の値を追跡するセット用:
home = (51.5074, -0.1278) # 緯度、経度
office = (51.5155, -0.0922)
home_lat, home_lon = home
print(f"Home: {home_lat}, {home_lon}")
# 一意の訪問者をセットで追跡
visitors = set()
visitors.add("alice")
visitors.add("bob")
visitors.add("alice") # 既にセットにあります、静かに無視されました
visitors.add("carol")
print(f"Unique visitors: {len(visitors)}")
print(f"alice visited: {'alice' in visitors}")
print(f"dave visited: {'dave' in visitors}")