リスト
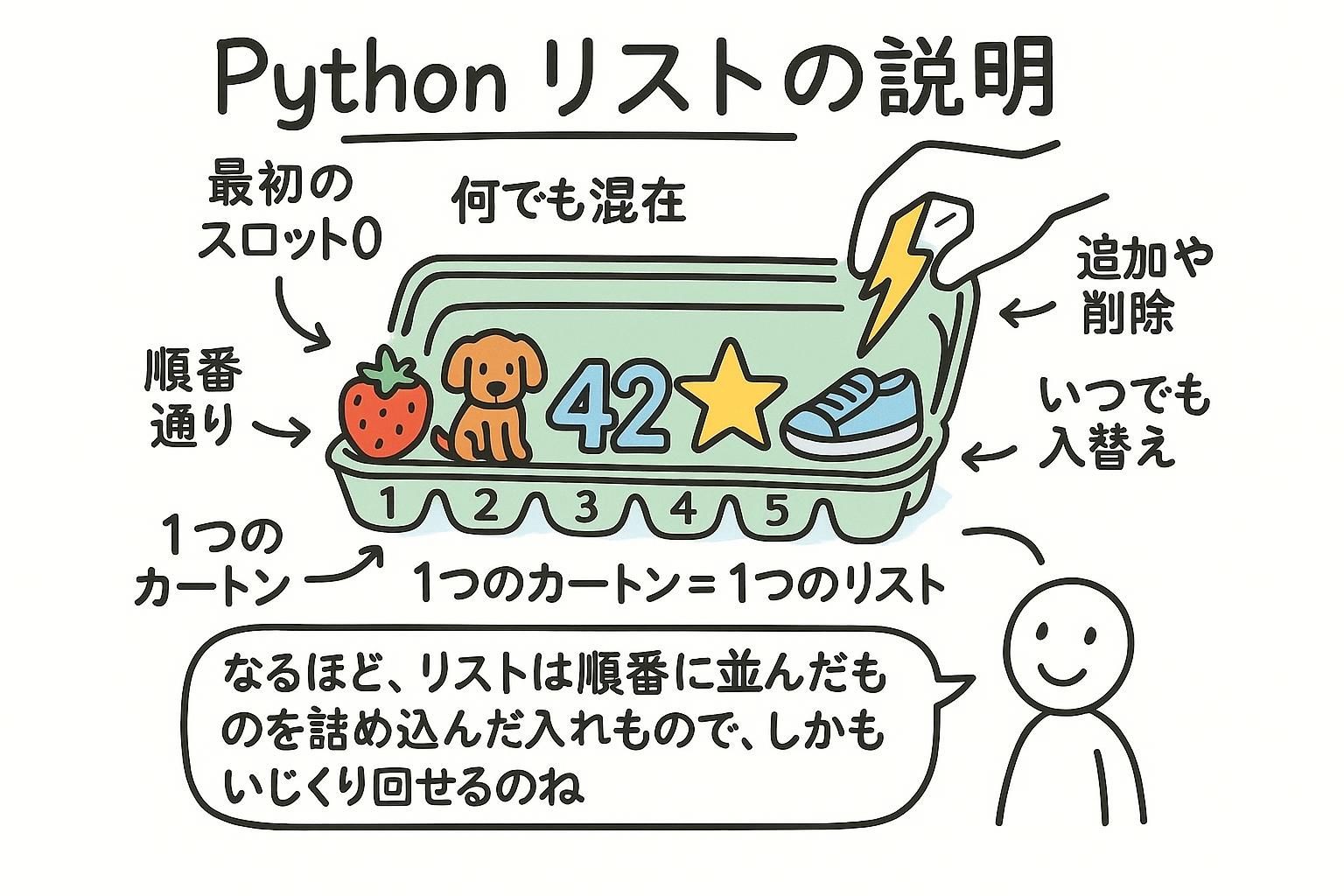
変数は1つのものを保持します。リストは多くのものを順序付けして保持し、すべて1つの名前の下にあります。リーダーボードはスコアの順位付きシーケンスです。クイズは質問の集合です。関連する値のグループを管理する必要が出てくると、リストが必要になります。
リストの作成
角括弧、カンマで区切られた値。リストはあらゆる種類の混合を保持できますし、空のリストは有効で、時間をかけて構築する開始点として一般的です。
scores = [87, 92, 74, 65, 91]
players = ["太郎", "花子", "次郎"]
mixed = ["太郎", 87, True, 3.14] # 任意の型、ただし一般的ではない
empty = []
[]は、あなたが行く際にそれを埋める計画があるときの良い開始点です。私のほとんどのリストはそのように開始します。空で待機中です。 インデックス処理とスライシング
リストは文字列と同じ番号付けを使用します:位置は0から始まり、負の数は末尾から数えます。位置によってあらゆるアイテムを読み取ります。リストは可変性があるため、特定の位置に書き込むこともできます。
scores = [87, 92, 74, 65, 91]
scores[0] # 87 (最初)
scores[-1] # 91 (最後)
scores[1:3] # [92, 74]
scores[:2] # [87, 92]
scores[::-1] # [91, 65, 74, 92, 87] (逆順)
scores[0] = 90 # 可変性:機能する(文字列はTypeErrorを発生させます)0で開始します。負の数は末尾から逆算します。したがってscores[-1]は最後のものです。scores[1:3]のようなスライスは、位置1と2を含む新しいリストを渡します。私が一瞬かかった部分:リストを使用して、位置に書き込むこともできます。scores[0] = 90は文字列が拒否する場所です。 アイテムの追加
アイテムを追加する3つの方法。append()は単一のアイテムを末尾に追加し、ほとんどいつもあなたが使用するものです。insert()は特定の位置に追加します。extend()は別のリストをマージします。
scores = [87, 92, 74]
scores.append(65) # [87, 92, 74, 65]
scores.insert(1, 100) # [87, 100, 92, 74, 65]
scores.extend([55, 71]) # [87, 100, 92, 74, 65, 55, 71]一般的な間違い:リストでappend()を行うと、リスト全体が1つのアイテムとして追加され、リスト内にリストが与えられます。代わりにextend()を使用してマージしてください:
scores.append([55, 71]) # [..., [55, 71]] ネストされたリスト、おそらく間違い
scores.extend([55, 71]) # [..., 55, 71] マージされた、正しいappend()は1つのアイテムを末尾にくっつけ、ほぼ毎回あなたが到達するものです。insert()は位置にアイテムをドロップします。extend()は別のリストをマージします。古典的なスリップ:append()するリストとあなたはリスト内にリストを取得します。マージするときはextend()を使用してください。 アイテムの削除
アイテムを削除するための4つのツール。remove()は値で検索します。pop()は位置で削除し、アイテムを返します。delは位置で削除し、戻り値はなく。clear()はリスト全体を空にします。
scores = [87, 92, 74, 65, 91]
scores.remove(74) # 74の最初の出現を削除
scores.pop() # 最後のアイテムを削除して返す(91)
scores.pop(0) # 位置0のアイテムを削除して返す(87)
del scores[1] # 位置1で削除、戻り値なし
scores.clear() # すべてを削除値がリスト内にない場合、remove()はValueErrorを発生させます。確実でない場合は最初にinで確認してください:
if 74 in scores:
scores.remove(74)remove()は値で削除し、最初のマッチのみを削除し。値がそこにない場合ValueErrorを発生させます。確実でない場合は最初にinで確認してください。pop()は位置で削除し、アイテムを返します。delは位置で削除し、あなたに何も与えません。 ソート
sorted()は新しいソート済みリストを返し、元のリストはそのまま残ります。.sort()はリストを所定位置でソートし、Noneを返します。その違いは聞こえるよりも重要です。
scores = [87, 42, 96, 55, 71]
ranked = sorted(scores) # [42, 55, 71, 87, 96] (新しいリスト)
scores.sort() # 所定位置でソート、Noneを返す
scores.sort(reverse=True) # [96, 87, 71, 55, 42]
result = scores.sort() # resultはNoneであり、ソート済みリストではないsorted()は新しいソート済みリストを与え、元のリストを単独で残します。.sort()はリストを再配置し、Noneを返すため、x = scores.sort()はあなたをNoneで着地させます。リストではありません。その正確な間違いを1回以上の後に行いました。それは固まりました。 便利な操作
Pythonには、リストで直接機能する組み込みツールのセットがあります。len()、sum()、min()、およびmax()は、あなたが常に到達する4つです。
scores = [87, 92, 74, 65, 91]
len(scores) # 5
sum(scores) # 409
min(scores) # 65
max(scores) # 92
scores.count(87) # 1
scores.index(74) # 2
74 in scores # True
74 not in scores # False
scores.copy() # 浅いコピー
scores.reverse() # 所定位置で逆順len()、sum()、min()、およびmax()はすべてリストで直接機能します。セットアップなし。inは何かが存在するかどうかを尋ね、.count()は何回かを数え、そして.index()は最初のマッチの位置を見つけます。 反復処理
forループはリストを一度に1つのアイテムで移動します。forの後の変数は順番に各アイテムを受け取ります。位置も必要な場合、enumerate()は手動カウンターがなく両方を与えます。
players = ["太郎", "花子", "次郎"]
for player in players:
print(player)
for i, player in enumerate(players, start=1):
print(f"{i}. {player}")
# 1. 太郎
# 2. 花子
# 3. 次郎forとenumerate()はControl flow章で完全に扱われています。短いバージョン:for player in playersはアイテムごとに1回実行し、enumerate()はすべての反復で位置と値の両方を与えます。
ネストされたリスト
リストは他のリストを含むことができます。これは、グリッドまたはテーブルを表す方法です:行のリスト、各行が値のリストです。2つの角括弧のセットがアイテムにアクセスします:最初が行を選択し、2番目が列を選択します。
grid = [
[1, 2, 3],
[4, 5, 6],
[7, 8, 9],
]
grid[0] # [1, 2, 3]
grid[1][2] # 6 (行1、列2)可変性:落とし穴
これはほぼ全員を驚かせます。リストを新しい変数に割り当てることはコピーを作成しません。両方の名前は同じリストをポイントします。1つを変更すると、もう1つを変更します。独立したコピーを取得するには、明示的に要求する必要があります。
a = [1, 2, 3]
b = a # bはコピーではありません;それは同じリストをポイントします
b.append(4)
print(a) # [1, 2, 3, 4] (変更:aおよびbは同じリスト)b = a.copy() # 独立したコピー
b = list(a) # 同じ結果
b = a[:] # また同じ
# ネストされたリストはまだ内側のオブジェクトを共有:
matrix = [[1, 2], [3, 4]]
copy = matrix.copy()
copy[0].append(99)
print(matrix) # [[1, 2, 99], [3, 4]] (内側のリストが共有された)b = aはコピーを作成しません。両方の名前は同じリストをポイントし、1つを通じた変更は他に表示されます。独立したリストについては、あなたは求める必要があります。.copy()、list(a)、またはa[:]。これは最初に誰もがほぼ驚いており、私も含まれます。 更多方法
| メソッド | 動作 |
|---|---|
.append(item) | 末尾に追加 |
.insert(i, item) | 位置iに挿入 |
.extend(iterable) | イテラブルからすべてのアイテムを追加 |
.remove(value) | 値の最初の出現を削除 |
.pop(i) | 位置iのアイテムを削除して返す(デフォルト:最後) |
.clear() | すべてのアイテムを削除 |
.index(value) | 最初の出現の位置 |
.count(value) | 出現数 |
.sort() | 所定位置でソート |
.reverse() | 所定位置で逆順 |
.copy() | 浅いコピーを返す |
実践
スコアトラッカーを構築:結果を追加、ソート、概要を印刷します。
scores = []
scores.append(87)
scores.append(54)
scores.append(92)
scores.append(67)
scores.append(45)
scores.sort(reverse=True)
print(f"Ranked scores: {scores}")
print(f"Highest: {scores[0]}")
print(f"Lowest: {scores[-1]}")
print(f"Average: {sum(scores) / len(scores):.1f}")
print(f"Top 3: {scores[:3]}")