변수와 타입
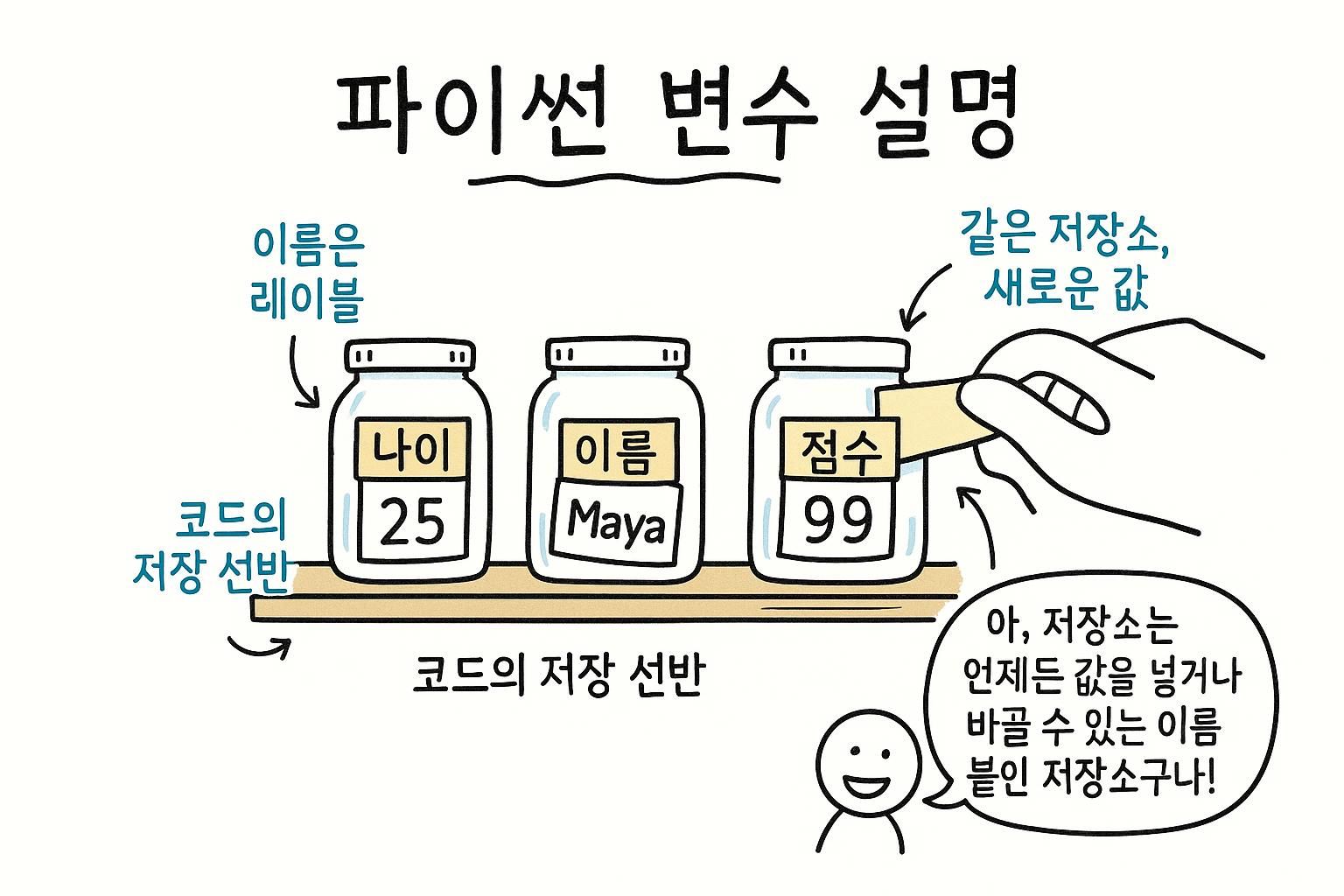
모든 프로그램은 뭔가를 기억해야 합니다. 퀴즈는 플레이어의 이름을 기억해야 합니다. 게임은 현재 점수를 기억해야 합니다. 날씨 스크립트는 확인하는 도시를 기억해야 합니다. Python은 이를 위해 변수를 사용합니다. 프로그램 전체에서 사용할 수 있도록 값에 붙이는 이름입니다.
player_name = "민지"
score = 0
city = "서울"세 줄, 세 가지를 Python이 이제 기억합니다. 각각에 대해 Python은 우측의 값을 먼저 계산한 후 좌측의 이름 아래에 저장합니다. 나중에 해당 이름을 사용하면 Python이 값을 되돌려줍니다.
값 저장하기
= 기호는 수학 수업에서 온 거의 모든 사람을 헷갈리게 합니다. Python에서 =는 "같다"라는 뜻이 아닙니다. **이 값을 이 이름 아래에 저장하라**는 뜻입니다:
city = "서울"city가 "서울"을 얻습니다. Python에게 말하는 것입니다: "서울"을 기억하고 city라고 표시하세요.
언제든지 변수의 값을 바꿀 수 있습니다. Python은 가장 최근의 값을 사용합니다:
score = 0
score = 10 # score는 이제 10
score = 15 # score는 이제 15
=는 수학 수업의 "같다"가 아니라 "이 값을 이 이름 아래에 숨겨라"입니다. 언제든지 변경하고 Python은 가장 최신의 값을 유지합니다. 선언도 설정도 없고, 이름을 지으면 존재합니다. 이 점을 과도하게 생각하지 않으려고 하는 데 정말 오래 걸렸습니다. 변수 이름 지정하기
이름을 선택합니다. Python은 몇 가지 엄격한 규칙을 가지고 있으며, 커뮤니티는 처음부터 채택할 가치가 있는 관례를 따릅니다. 명확한 이름은 몇 주 후에 코드를 읽을 수 있게 합니다. 암호화된 이름은 고통을 야기합니다.
Python이 시행하는 규칙:
- 문자, 숫자, 밑줄만 가능합니다. 공백이나 하이픈은 없습니다.
- 문자나 밑줄로 시작해야 하며, 숫자로 시작할 수 없습니다
- 대소문자 구분:
score,Score,SCORE는 세 개의 다른 변수입니다
모두가 따르는 관례 (PEP 8):
| 것 | 스타일 | 예 |
|---|---|---|
| 변수와 함수 | snake_case | user_name, total_price |
| 상수 | UPPER_SNAKE_CASE | MAX_RETRIES, BASE_URL |
| 클래스 | PascalCase | UserAccount, DataLoader |
# 명확한 이름, 한 눈에 읽을 수 있음
user_name = "민지"
total_price = 49.99
is_logged_in = True
MAX_RETRIES = 3
# 한 시간 안에 후회할 것들
x = "민지"
tp = 49.99
b = True일찍 알아야 할 함정 하나: list, input, type, print 같은 Python 내장 함수 이름으로 변수를 이름 짓지 마세요. Python은 이를 허용하지만 그 범위의 나머지에서 내장 함수를 조용히 깨고 결과 오류는 추적하기 어렵습니다.
snake_case를 따르면 됩니다. 초보자 실수 하나: 변수를 list나 print라고 부르지 마세요. Python이 허용하면 나중에 모든 것이 이상해집니다. 경고도 없이요. 저장할 수 있는 것
Python은 거의 모든 프로그램에서 사용할 네 가지 타입을 가지고 있습니다. Python은 값을 어떻게 쓰는지에 따라 어느 타입을 의도했는지 파악합니다. 타입을 명시적으로 선언할 필요가 없습니다.
텍스트 (str)
모든 텍스트는 따옴표 안에 갑니다. 단일 또는 이중 따옴표입니다. 따옴표는 Python에게 리터럴 문자를 의도한다는 것을 알립니다. 변수 이름이 아닙니다. 문자열은 생성되면 제자리에서 변경될 수 없습니다. Strings 장은 문자열로 할 수 있는 모든 것을 다룹니다.
player_name = "민지"
city = "서울"
message = 'Game over'텍스트에 아포스트로피가 포함되어 있으면 이중 따옴표를 사용하여 이스케이프할 필요가 없습니다:
note = "It's a great day"
note = 'It\'s a great day' # 이스케이프를 사용하면 같은 결과정수 (int)
정수는 따옴표 없이 소수점 없이 입력합니다. Python은 이를 정수라고 부릅니다. 필요한 만큼 클 수 있습니다. Python은 특별한 노력 없이 임의로 큰 숫자를 처리합니다.
score = 0
age = 28
population = 8_100_000_000 # 밑줄은 가독성을 위해서만 사용됨소수 (float)
소수점이 있는 숫자는 float입니다. 대부분의 계산에서 예상대로 작동합니다. 알아야 할 한 가지: 일부 소수 값은 이진법으로 정확히 저장할 수 없으므로 작은 반올림 오류가 생길 수 있습니다:
price = 4.99
temperature = 36.6
0.1 + 0.2 # 0.30000000000000004일상 업무의 경우 이는 거의 중요하지 않습니다. 센트의 분수가 중요한 금융 계산의 경우 Python은 올바르게 처리하는 decimal 모듈을 가지고 있습니다. 이는 Numbers 장에서 다룹니다.
참 또는 거짓 (bool)
일부 것은 켜지거나 꺼집니다. Python은 이를 위해 부울을 사용합니다: 정확히 두 값, True와 False. 이 단계에서는 사소해 보이지만 프로그램의 모든 조건과 분기는 부울에서 실행됩니다.
is_logged_in = True
has_errors = FalsePython은 조건에서 사용할 때 특정 값을 False인 것처럼 처리합니다: 0, 0.0, "", None(Python의 "여기에 값이 없음")은 모두 False처럼 동작합니다. 다른 모든 것은 True처럼 동작합니다. 이것은 Control flow 장에서 유용하게 됩니다.
타입 확인 및 변환
값의 타입이 확실하지 않을 때 type()이 알려줍니다. 값이 특정 타입인지 확인하려면 isinstance()가 더 신뢰할 수 있는 도구입니다:
print(type("hello")) # <class 'str'>
print(type(42)) # <class 'int'>
print(type(3.14)) # <class 'float'>
print(type(True)) # <class 'bool'>
isinstance(42, int) # True
isinstance("hi", str) # TruePython은 타입을 자동으로 혼합하지 않습니다. 문자열과 숫자를 연결하면 TypeError가 발생합니다:
score = 42
print("Your score is " + score) # TypeError
print("Your score is " + str(score)) # 작동함타입 이름을 함수로 사용하여 명시적으로 변환하세요:
| 호출 | 결과 |
|---|---|
str(42) | "42" |
int(3.9) | 3 (자르기, 반올림 아님) |
float("3.14") | 3.14 |
int("3.14") | ValueError: 10진 문자열을 정수로 직접 변환할 수 없습니다 |
int(float("3.14")) | 3 (먼저 float로 변환한 후 int로) |
bool(0) / bool("") | False |
실제로
네 가지 타입 모두 작은 스크립트에서 함께 작동합니다. 출력 줄은 f-문자열을 사용하여 텍스트에 값을 포함합니다. 여는 따옴표 전에 f를 넣고 모든 변수를 {}로 감싸세요. Python은 변수의 실제 값으로 대체합니다. 다음 장에서 올바르게 배웁니다.
player_name = "민지"
level = 3
accuracy = 0.94
is_premium = True
print(f"{player_name}는 {accuracy:.0%} 정확도로 {level}단계에 있습니다.")
print(f"프리미엄 계정: {is_premium}")타입은 중요합니다. level + 1은 작동하지만 player_name + 1은 작동하지 않습니다. 각 변수는 정확히 한 종류의 것을 담습니다. Python은 자동으로 혼합하지 않습니다.