Dicionários
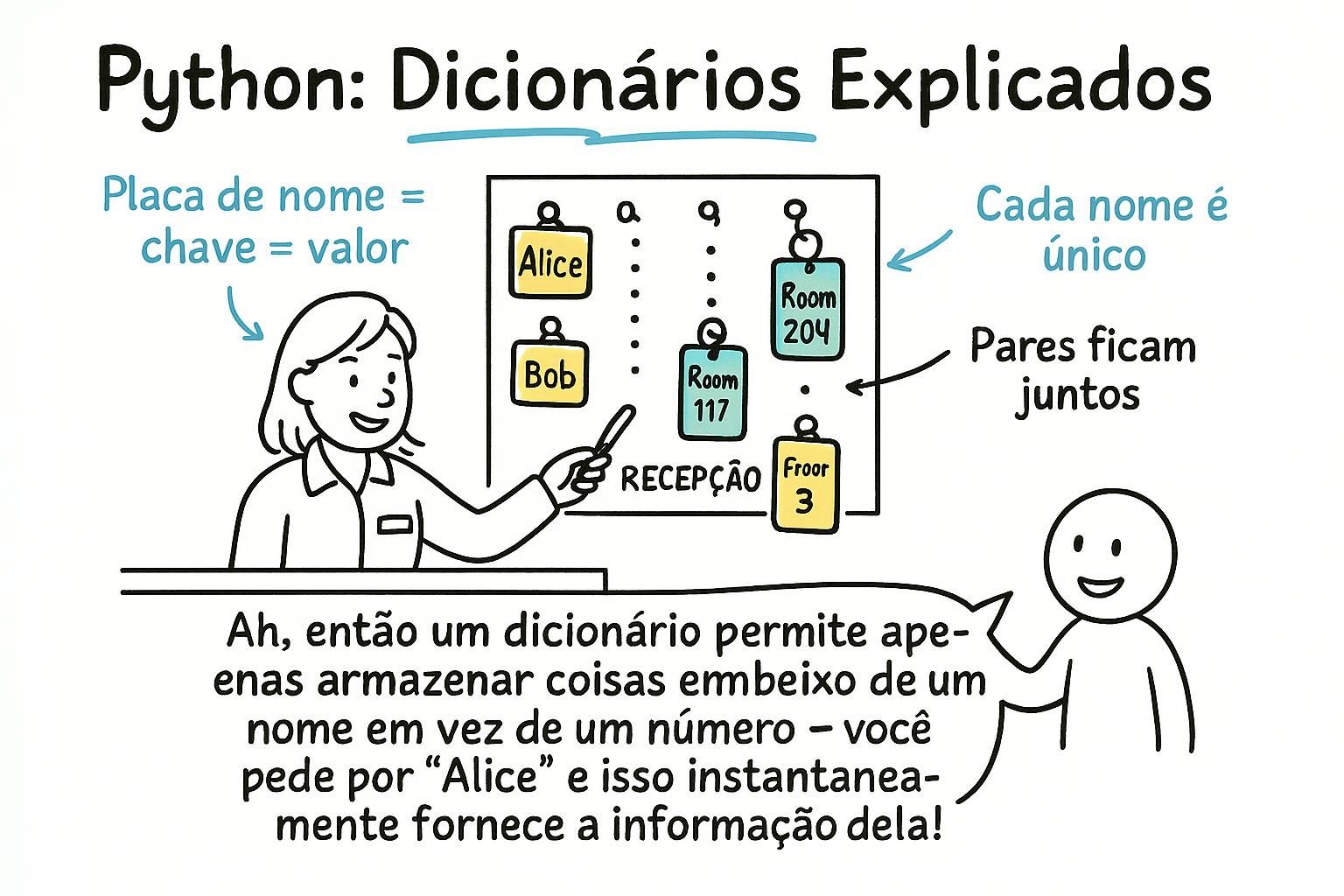
Listas permitem procurar coisas por posição. Mas frequentemente você quer procurar algo pelo nome. Não "me dê o item 3", mas "me dê a pontuação de Maria". Um dicionário armazena dados como pares chave-valor: você procura um valor por sua chave, não por sua posição.
Criando um dicionário
Chaves com um dois-pontos entre cada chave e valor, e vírgulas entre pares. As chaves são quase sempre strings. Os valores podem ser qualquer coisa: números, strings, outras listas, até outros dicionários.
player = {
"name": "Maria",
"score": 87,
"level": 5,
"alive": True,
}
Acessando valores
Use colchetes com a chave para obter o valor. Se a chave não existe, Python levanta um KeyError. Use .get() quando você não tem certeza de que a chave está lá: ela retorna None em vez de travar, ou um valor padrão que você especifica.
player = {"name": "Maria", "score": 87}
player["name"] # "Maria"
player["score"] # 87
player["lives"] # KeyError (chave não existe)player.get("score") # 87
player.get("lives") # None (sem erro, retorna None por padrão)
player.get("lives", 3) # 3 (use este padrão se a chave estiver ausente).get() é mais seguro sempre que uma chave pode estar ausente:
count = inventory.get("arrows", 0) # 0 se "arrows" não estiver no dictd["key"] lhe dá o valor, mas levanta KeyError se essa chave não estiver lá. Quando você não tem certeza, use .get(): ela retorna None em vez de travar, ou um padrão que você passa. Agora eu uso `.get()` para tudo e meus programas pararam de travar em chaves ausentes. Adicionando e atualizando
Atribua a uma chave com colchetes. Se a chave já existe, o valor é substituído. Se ela ainda não existe, uma nova entrada é criada. Use .update() para mesclar um dicionário inteiro de uma vez.
player = {"name": "Maria", "score": 87}
player["score"] = 92 # atualizar existente
player["level"] = 5 # adicionar nova chaveextras = {"level": 5, "alive": True}
player.update(extras) # adiciona/sobrescreve com chaves de extras.update() para incorporar um dicionário inteiro de uma vez. Removendo itens
Quatro maneiras de remover entradas. .pop() remove uma chave e lhe dá o valor de volta. .pop() com um padrão é seguro quando a chave pode não estar lá. del remove uma chave sem valor de retorno. .clear() esvazia o dicionário inteiro.
player = {"name": "Maria", "score": 87, "level": 5}
player.pop("level") # remove "level" e retorna 5
player.pop("lives", None) # pop seguro, retorna None se chave ausente
del player["score"] # remove "score", sem valor de retorno
player.clear() # remove tudo.pop() com um padrão é a forma mais segura de remover uma chave que pode não existir.
.pop(key) remove uma chave e lhe dá seu valor de volta, e .pop(key, None) fica calmo quando a chave pode não estar lá. del d[key] remove sem retornar nada, .clear() esvazia tudo. O padrão em .pop() me salvou de muitas surpresas de KeyError. Iterando
Três visualizações permitem fazer loop em diferentes partes de um dicionário. Iterar o dict diretamente lhe dá as chaves. .values() dá valores. .items() dá ambas de uma vez e é o que você usará mais: desempacote cada par em dois nomes para loops limpos e legíveis.
player = {"name": "Maria", "score": 87, "level": 5}
for key in player: # iterar chaves (mais comum)
print(key)
for key in player.keys(): # o mesmo, visualização de chaves explícita
print(key)
for value in player.values(): # os valores
print(value)
for key, value in player.items(): # ambas, mais útil
print(f"{key}: {value}").items() é o que você usará mais. Desempacotar cada par em dois nomes torna o loop legível.
.values() dá os valores, e .items() dá ambas de uma vez, que é o que você alcançará mais. Desempacotar cada par em dois nomes como for key, value in player.items() tornou meus loops muito mais fáceis de ler. Verificando associação
in verifica se uma chave existe no dicionário. Ela não verifica valores, apenas chaves. Para verificar se algo não está presente, use not in.
player = {"name": "Maria", "score": 87}
"name" in player # True
"lives" in player # False
"lives" not in player # Truein apenas verifica chaves. Para verificar valores, use in player.values(), embora isso seja raramente necessário.
in lhe diz se uma chave está no dict, e apenas uma chave, nunca um valor. Ela permanece rápida não importa o tamanho do dict. Inverta para not in para verificar que algo está ausente. Dicionários aninhados
Os valores podem ser dicionários em si. É assim que você representa dados estruturados com múltiplos níveis: um jogador que tem uma seção de stats, um arquivo de config com sub-seções. Dois conjuntos de colchetes acessam um valor aninhado: o primeiro escolhe a chave externa, o segundo escolhe a chave interna.
users = {
"alice": {"score": 87, "level": 5},
"bob": {"score": 74, "level": 3},
}
users["alice"]["score"] # 87
users["bob"]["level"] # 3Acesse com colchetes quadrados encadeados. Para estruturas muito aninhadas, isso pode ficar desajeitado, então mantenha o aninhamento raso onde você puder.
setdefault
.setdefault() lê uma chave se ela existe, ou a define para um valor padrão se não, então retorna o valor. É útil quando você precisa de uma chave para existir mas não quer sobrescrevê-la se ela já está lá.
inventory = {}
inventory.setdefault("arrows", 0) # define "arrows": 0, retorna 0
inventory.setdefault("arrows", 10) # "arrows" já existe, sem mudança, retorna 0É útil para construir estruturas agrupadas sem verificar a existência da chave primeiro:
groups = {}
for name, team in players:
groups.setdefault(team, []).append(name).setdefault(key, default) lê uma chave se ela está lá, ou a define para o padrão e a retorna se não estiver. É a forma arrumada de se certificar de que uma chave existe sem clobbering um valor que já está lá. Eu a uso mais para agrupar coisas, sem verificação "esta chave está aqui ainda?" necessária. collections.defaultdict e Counter
A biblioteca padrão tem duas subclasses de dict que lidam com padrões comuns automaticamente. defaultdict cria um valor padrão para chaves ausentes para que você nunca obtenha um KeyError. Counter conta com que frequência cada item aparece em uma sequência e lhe dá os resultados como um dict.
defaultdict e Counter vivem na biblioteca padrão, então eles precisam de importação primeiro. As importações recebem tratamento completo no capítulo Módulos.
from collections import defaultdict
groups = defaultdict(list)
for name, team in players:
groups[team].append(name) # sem KeyError se team é novofrom collections import Counter
words = ["cat", "dog", "cat", "bird", "cat", "dog"]
counts = Counter(words)
# Counter({'cat': 3, 'dog': 2, 'bird': 1})
counts.most_common(2) # [('cat', 3), ('dog', 2)]Counter economiza muita tabulação "conte coisas em um loop".
defaultdict preenche um padrão para qualquer chave ausente, portanto agrupamento e contagem param de lançar KeyError em você. Counter tally com que frequência cada item aparece em uma sequência e o entrega de volta como um dict. A primeira vez que troquei um loop de contagem escrito à mão por Counter, metade do meu código desapareceu. Na prática
Construindo um rastreador de pontuação e imprimindo um resumo com todas as entradas:
scores = {"Maria": 87, "João": 74, "Carol": 92, "Dave": 55}
total = sum(scores.values())
average = total / len(scores)
print(f"Jogadores: {len(scores)}")
print(f"Média: {average:.1f}")
print(f"Maior: {max(scores.values())}")
print(f"Menor: {min(scores.values())}")
print()
for name, score in scores.items():
print(f" {name}: {score}")